
自注意力对齐:使用自注意力网络和跳块的一种延时控制的端到端语音识别模型
为什么我们需要为NLG设计新的自动化评估指标
利用多轮问答模型处理实体-关系抽取任务
倾听“声音”的声音:一种用于声音事件检测的“时间-频率”注意力模型
用于端到端流式语音识别的单向LSTM模型结构分析
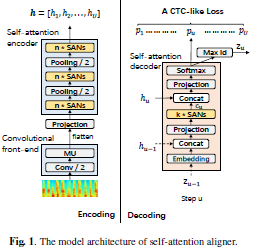
论文名称:self-attention aligner: a latency-control end-to-end model for ASR using self-attention network and chunk-hopping
作者:Linhao Dong / Feng Wang / Bo Xu
发表时间:2019/2/18
论文链接:https://paper.yanxishe.com/review/16749?from=leiphonecolumn_paperreview0420
推荐原因
为了解决RNN结构的语音识别模型存在的训练时间长、对一些噪音很敏感等问题,作者参考了transformer结构设计了一个语音识别模型,其中编码部分使用了时间维度的池化操作进行下采样来进行时间维度的信息交互并提高模型速度,解码的部分设计了一种模拟CTC的对齐结构。此外,作者将语音识别模型与语言模型进行端到端的联合训练,使得CER得到进一步提升。
将transformer结构应用语音识别,今天已经不新鲜了。但是就去年本文发表的时期而言,将另一个领域的优秀模型应用到本领域来,会遇到什么问题,要怎么解决这些问题,如何进行优化?本文的这些思路都是很值得参考的。比如,transformer模型能很好的解决文本类的NLP任务,那么将其与语音识别联合训练,也更有可能收敛,以达到提高表现的目的。

论文名称:Why We Need New Evaluation Metrics for NLG
作者:Jekaterina Novikova / Ondrej Du ˇ sek / Amanda Cercas Curry ˇ / Verena Rieser
发表时间:2017/7/21
论文链接:https://paper.yanxishe.com/review/16619?from=leiphonecolumn_paperreview0420
推荐原因
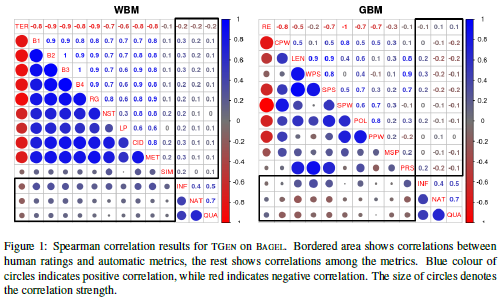
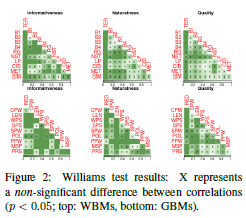
核心内容: 作者针对NLG(nature language generation)自动化评估问题,对于WBMs(Word-based Metrics), GBMs(Grammar-based metrics)两大类总计21个当时常用的评估指标进行了分析,具体是用了3个SOTA模型以及三个属于不同领域的数据集上进行测试,并且将测试结果进一步交由众包平台进行人工打分,进而对自动评估和人工评估进行有效性对比以及关联性分析。同时,对于测试结果进行了模型、数据集、以及具体样本级别的详细错误分析,得出了包括BLEU在内的大部分指标并不能令人满意的结论。
文章亮点:系统地分析了自动评估与人工评估关联性及其在不同数据集上的表现;作者公开了全部的代码、数据以及分析结果。
推荐理由:设计一个模型的时候,对数据集进行分析是理所当然的,对于当前的自动化评估指标是否适用于数据集就没那么直观了,本文对于如何设计出一个令人满意的NLP模型给人以启发。
论文名称:Entity-Relation Extraction as Multi-turn Question Answering
作者:Xiaoya Li / Fan Yin / Zijun Sun / Xiayu Li / Arianna Yuan /Duo Chai / Mingxin Zhou and Jiwei Li
发表时间:2019/9/4
论文链接:https://paper.yanxishe.com/review/15956?from=leiphonecolumn_paperreview0420
推荐原因
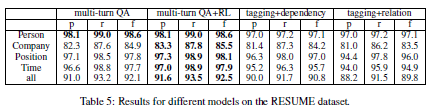
如今NLP领域很多研究人员将非QA(question answer)的任务转换成QA问题,取得了不错的效果,受此启发,作者提出了使用设计了一种问答模型的新模式来处理事件抽取任务,其核心部分是:针对首实体(head entity)和关系(relation)分别设计了一种将实体转换为问题(question)的模板,并通过生成答案(answer)来依次抽取head entity和整个三元组。同时,本文参考了对话系统中利用强化学习来进行多轮任务的思想,设计了多轮问答模型。
本文涉及到事件抽取、问答系统、阅读理解、强化学习等多个NLP方面的知识,并提出了一个有利于事件抽取的中文数据集,在多个数据集上均达到了新的SOTA。
从作者的数量能看出,他们做了大量的工作,对于个人来说可能很难复现他们的实验,但是其融合NLP多个领域来进行模型的优化的思想,很值得学习。
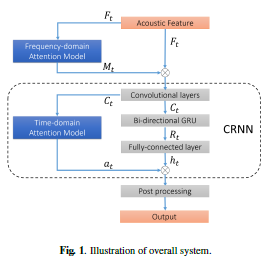
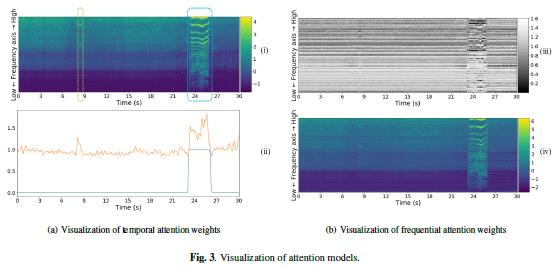
论文名称:Learning How to Listen: A Temporal-Frequential Attention Model for Sound Event Detection
作者:Yu-Han Shen / Ke-Xin He / Wei-Qiang Zhang
发表时间:2018/10/29
论文链接:https://paper.yanxishe.com/review/15418?from=leiphonecolumn_paperreview0420
推荐原因
这篇文章被 ICASSP 2019收录,核心内容是作者作为一个参赛者对DCASE2017中的一个特殊语音事件检测任务的分析,作者的思路是利用attention机制,提取出声音信号中最为重要的特征,并且从单个frame的频谱特性( spectral characteristic)以及样本中多个frames的时间特性的角度设计注意力模型,使用maxpooling将一段声音中的关键特征抽取出来。
从比赛结果来看,作为没有使用集成学习的单个模型,作者提出的这种模型结构所得到的分数是比赛中最优的。
本文不仅模型设计的很出色,对于数据不均衡、音频噪声等问题的处理也值得一读。
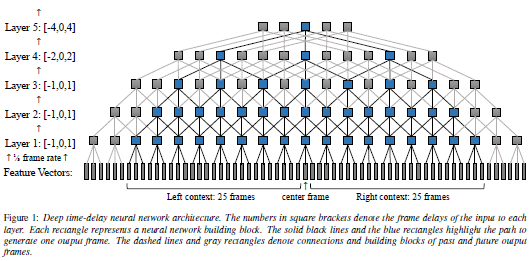
论文名称:Unidirectional Neural Network Architectures for End-to-End Automatic Speech Recognition
作者:Niko Moritz / Takaaki Hori / Jonathan Le Roux
发表时间:2019/9/19
论文链接:https://paper.yanxishe.com/review/15822?from=leiphonecolumn_paperreview0420
推荐原因
端到端ASR模型中,以往的语音识别模块结构变成了单一的神经网络,这要求模型能处理更长的上下文信息,目前,双向LSTM(BiLSTM)已经在这方面取得了相当好的效果,但是并不适合流式语音识别。作者以此为出发点,讨论了现在流行的几种单向LSTM网络模型以及基于延时控制(latency-controlled)的BiLSTM,并且以此为基础提出了两种更好的TDLSTM(time-delayed LSTM),并且在中英文语音数据集上进行了验证。
本文专门讨论网络模型设计,一方面,为了保证公平,对作为baseline的模型均做了一些优化,同时简化了输入输出模块,除了“Kaldi”-TDNN-LSTM模型在大型训练集上出现了内存溢出,其他模型均在包括延时控制、模型参数数量等方面均很接近的条件下进行训练,另一方面,作者对于如何设计一个满足需求的神经网络模型讲解的很细致,有一种读教材的感觉。因此,我还特意去搜到这个作者的个人网站,的确是个牛人http://www.jonathanleroux.org/。
现AI 研习社已经和阿里大文娱、旷视、搜狗搜索、小米等知名公司达成联系,为帮助大家更好地求职找工作,社区成立了AI求职内推社群,找工作找实习的小伙伴可以扫码进群了,也欢迎在读的同学来交流学习。(群里有企业hr,项目招聘人员)

雷锋网雷锋网雷锋网
相关文章:

正在生成分享图...
 张璐
昨天 14:22
陈淑瑜
06月12日 16:38
郑佳美
06月12日 14:28
郑佳美
06月12日 14:25
张璐
昨天 14:22
陈淑瑜
06月12日 16:38
郑佳美
06月12日 14:28
郑佳美
06月12日 14:25