
CopyMTL: 命名实体识别和关系抽取多任务学习联合模型中的复制机制
学习(what,how,why)三元组: 一种几乎完美的基于方面的情感分析模型
胶囊网络来解释你喜欢什么不喜欢什么
XTREME:一个大规模的多语言多任务基准测试 用于评估跨语言概括
使用深度神经网络和组合优化对生理信号进行切分和最优波段选择
论文名称:CopyMTL: Copy Mechanism for Joint Extraction of Entities and Relations with Multi-Task Learning
作者:Daojian Zeng /Haoran Zhang /Qianying Liu
发表时间:2019/11/24
论文链接:https://paper.yanxishe.com/review/15955?from=leiphonecolumn_paperreview0417
推荐原因
CopyRE是一种基于seq2seq结构的非常优秀的关系抽取模型,作者针对CopyRE存在的首尾实体(head and tail entities)无法区分、无法匹配多字符实体(multi-tokens entity)的问题进行了分析,并且提出了自己的改进模型CopyMTL。
作者详细的讲解了CopyRE的原理,并从理论的角度分析了CopyRE存在如上问题的原因,进而使用以selu为激活函数的全连接层解决了首尾实体无法区分的问题,使用结合了NER的多任务学习来解决无法匹配多字符实体的问题,同时在多个数据集上达到了SOTA。
这里使用多任务学习来优化CopyRE,并且给出了代码,从文章上来看,应该是根据CopyRE作者的代码进行改进的,对于想利用多任务学习来优化自己模型的同学有很大的参考意义
此外,提个疑问,如果反过来,是不是也可以使用copy mechanism来优化基于序列标注的关系抽取模型呢?
论文名称:Knowing What, How and Why: A Near Complete Solution for Aspect-based Sentiment Analysis
作者:Haiyun Peng /Lu Xu /Lidong Bing /Fei Huang /Wei Lu /Luo Si
发表时间:2019/11/5
论文链接:https://paper.yanxishe.com/review/16070?from=leiphonecolumn_paperreview0417
推荐原因
本文的核心内容是由阿里巴巴达摩研究院提出的一个三元组抽取模型,并以此将方面信息抽取(aspect extraction)、方面所属情感种类(aspect term sentiment classification)、态度词(opinion term extraction)等子任务合并在一个模型中解决。其主要的思路是定义一个包含了方面、情感、态度词信息的三元组
本文在模型设计方面有很多值得深思的亮点,简单说几个让我印象最深的,其一,第一个序列标注任务仅标注边界信息(boundary information),同时利用边界信息,在方面序列标注任务使用了softmax作为输出,而不是CRF。其二,针对态度词的的特点,在其序列标注任务中,先使用了一个GCN(Graph Convolutional Network)来学习其语义信息。其三,利用方面序列标注任务的信息来指导态度词序列标注任务。此外还有精心设计的BLSTM模型结构、多义词处理、预训练词向量等。
这个模型在各个子任务中都达到了SOTA,作者开源了一些三元组数据,但是没有提供完整的代码。
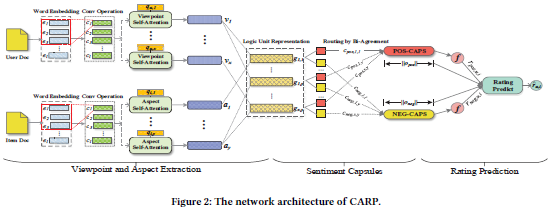
论文名称:A Capsule Network for Recommendation and Explaining What You Like and Dislike
作者:Chenliang Li
发表时间:2019/2/1
论文链接:https://paper.yanxishe.com/review/14886?from=leiphonecolumn_paperreview0417
推荐原因
本文主要研究目的和创新点:
本文针对用户的评论来预测用户的喜好,主要用在推荐系统中。目前已经有很多相关的研究,但是在采用深度学习建模的过程中,根据用户持有的观点依旧很难理解用户的喜好。在此基础上作者尝试性将用户持有的观点与对应的商品属性作为一个逻辑单元,对用户的评论进行挖掘,并进行用户喜好预测。为此,本文提出了一种基于带有用户评论的收视率预测模型,称为CARP。对于每个用户对,设计CARP来提取信息逻辑,并推断出相应的情感。为了验证模型效果,作者分别在7个真实数据集上进行了大量实验,实验表明,该模型对于用户喜好的预测精度有较大提升。
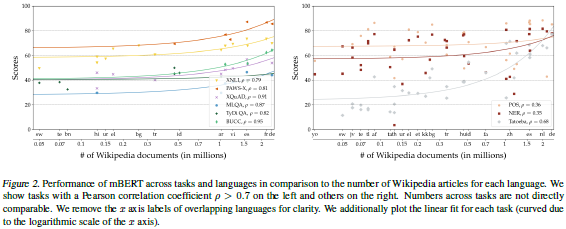
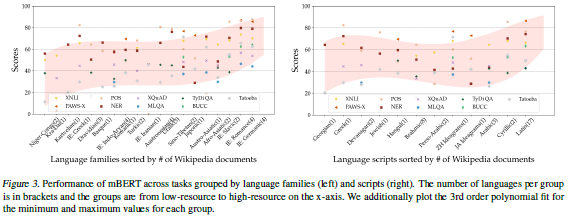
论文名称:XTREME: AMassively Multilingual Multi-task Benchmark for Evaluating Cross-lingual Generalization
作者:Junjie Hu / Sebastian Ruder /Aditya Siddhant /Graham Neubig /Orhan Firat
发表时间:2020/3/27
论文链接:https://paper.yanxishe.com/review/15688?from=leiphonecolumn_paperreview0417
推荐原因
核心问题:基准测试可以评估各种任务的模型,但是基准测试大多仅限于英语,所以缺少能够对各种语言和任务进行此类方法的综合评估的基准测试。通过英语测试的模型可以在许多任务上达到人类的表现,但跨语言转移的模型的表现仍然存在较大差距。
创新点:本论文介绍了多语言编码器的跨语言转换评估—XTREME 基准。作为一个多任务基准,XTREME 可以用于评估 40 种语言和 9 个任务的多语言表示形式的跨语言概括能力。
研究意义:他们发布了基准测试结果,以鼓励研究跨语言学习方法,希望这些方法可以跨各种代表性的语言和任务传递语言知识。
论文名称:Segmentation and Optimal Region Selection of Physiological Signals using Deep Neural Networks and Combinatorial Optimization
作者:Jorge Oliveira /Margarida Carvalho /Diogo Marcelo Nogueira /Miguel Coimbra
发表时间:2020/3/17
论文链接:https://paper.yanxishe.com/review/14660?from=leiphonecolumn_paperreview0417
推荐原因
1 核心问题
本文解决的是如何自动提取生理信号最优波段来辅助后续诊断和预测的问题。
2 创新点
本文使用神经网络去计算每个样本的状态概率分布,然后构造出一张图,同时在图中加入状态转换限制,并根据最大化用户提出的似然函数去使用一组约束来检索生理信号记录的子集。
3 研究意义
生理信号经常会被噪音干扰。通常情况下,人工智能算法会在无视质量的情况下对之进行整体分析。与之相反的是,医师则并不分析整个记录,而是会搜寻容易检测到基本波动和异常波动的波段进行分析,然后才进行预测。因此,受到以上事实启发,本文提出了一个基于用户自定标准,为后期处理自动选择最优波段的算法。本文将提出的方法使用在两个实际应用场景中,并且取得了很好的效果。
求职交流
现AI 研习社已经和阿里大文娱、旷视、搜狗搜索、小米等知名公司达成联系,为帮助大家更好地求职找工作,社区成立了AI求职内推社群,找工作找实习的小伙伴可以扫码进群了,也欢迎在读的同学来交流学习。

雷锋网雷锋网雷锋网

正在生成分享图...
 张璐
昨天 14:22
陈淑瑜
06月12日 16:38
郑佳美
06月12日 14:28
郑佳美
06月12日 14:25
张璐
昨天 14:22
陈淑瑜
06月12日 16:38
郑佳美
06月12日 14:28
郑佳美
06月12日 14:25