
12-in-1: 多任务视觉和语言表示学习
CVPR 2020 | 用于零样本超分辨率的元转移学习
CVPR 2020 | ABCNet:基于自适应Bezier-Curve网络的实时场景文本定位
CVPR 2020 | Sketch Less for More:基于细粒度草图的动态图像检索
CVPR 2020 | PointAugment:一种自动增强的点云分类框架
论文名称:12-in-1: Multi-Task Vision and Language Representation Learning
作者:Jiasen Lu
发表时间:2019/12/11
论文链接:https://paper.yanxishe.com/review/13547?from=leiphonecolumn_paperreview0324
推荐原因
本文研究意义:
当下AI模型的实验数据集都是小而多样的,这对于后续模型的训练都会造成很大的影响,在此背景下,本文介绍了一项新颖的数据调度方法——多任务模型,以帮助避免过度训练或训练不足。为了验证该方法是否可行,作者分别在12个视觉和语言数据集上进行了实验,结果表明,使用这种方法后,我们的单一多任务模型优于12个单一任务模型,这一新方法也为后续的研究带来了新潮流。

论文名称:Meta-Transfer Learning for Zero-Shot Super-Resolution
作者:Soh Jae Woong /Cho Sunwoo /Cho Nam Ik
发表时间:2020/2/27
论文链接:https://paper.yanxishe.com/review/12829?from=leiphonecolumn_paperreview0324
推荐原因
这篇论文被CVPR 2020接收,考虑的是零样本超分辨率的问题。
以往的零样本超分辨率方法需要数千次梯度更新,推理时间长。这篇论文提出用于零样本超分辨率的元转移学习。基于找到适合内部学习的通用初始参数,所提方法可以利用外部和内部信息,一次梯度更新就可以产生相当可观的结果,因此能快速适应给定的图像条件,并且应用于大范围图像。
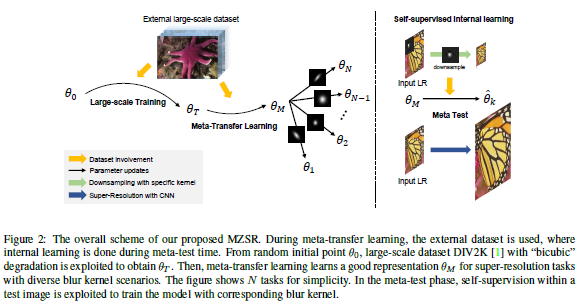

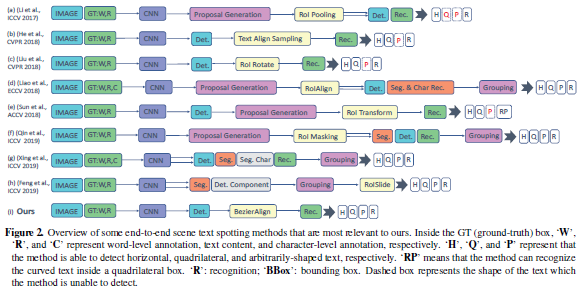
论文名称:ABCNet: Real-time Scene Text Spotting with Adaptive Bezier-Curve Network
作者:Liu Yuliang /Chen Hao /Shen Chunhua /He Tong /Jin Lianwen /Wang Liangwei
发表时间:2020/2/24
论文链接:https://paper.yanxishe.com/review/12441?from=leiphonecolumn_paperreview0324
推荐原因
这篇论文被CVPR 2020接收,考虑的是场景文本检测和识别的问题。
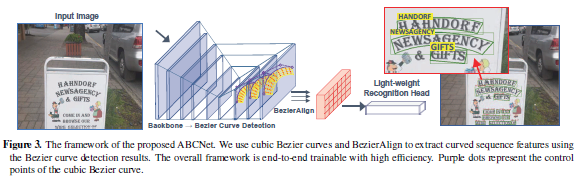
现有方法基于字符或基于分段,要么在字符标注上成本很高,要么需要维护复杂的工作流,都不适用于实时应用程序。这篇论文提出了自适应贝塞尔曲线网络(Adaptive Bezier-Curve Network ,ABCNet),包括三个方面的创新:1)首次通过参数化的贝塞尔曲线自适应拟合任意形状文本;2)设计新的BezierAlign层,用于提取具有任意形状的文本样本的准确卷积特征,与以前方法相比显著提高精度;3)与标准图形框检测相比,所提贝塞尔曲线检测引入的计算开销可忽略不计,从而使该方法在效率和准确性上均具优势。对任意形状的基准数据集Total-Text和CTW1500进行的实验表明,ABCNet达到当前最佳的准确性,同时显著提高了速度,特别是在Total-Text上,ABCNet的实时版本比当前最佳方法快10倍以上,且在识别精度上极具竞争力。
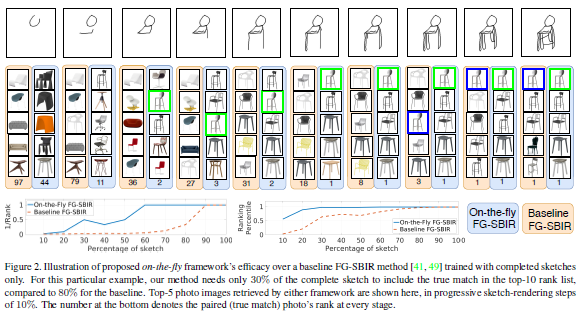
论文名称:Sketch Less for More: On-the-Fly Fine-Grained Sketch Based Image Retrieval
作者:Bhunia Ayan Kumar /Yang Yongxin /Hospedales Timothy M. /Xiang Tao /Song Yi-Zhe
发表时间:2020/2/24
论文链接:https://paper.yanxishe.com/review/12442?from=leiphonecolumn_paperreview0324
推荐原因
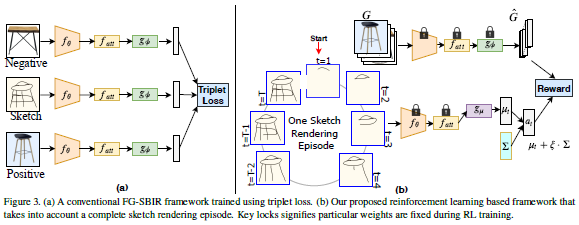
这篇论文被CVPR 2020接收,考虑的是基于草图的细粒度图像检索,即在给定用户查询草图的情况下检索特定照片样本的问题。
绘制草图花费时间,且大多数人都难以绘制完整而忠实的草图。为此这篇论文重新设计了检索框架以应对这个挑战,目标是以最少笔触数检索到目标照片。这篇论文还提出一种基于强化学习的跨模态检索框架,一旦用户开始绘制,便会立即开始检索。此外,这篇论文还提出一种新的奖励方案,该方案规避了与无关的笔画笔触相关的问题,从而在检索过程中为模型提供更一致的等级列表。在两个公开可用的细粒度草图检索数据集上的实验表明,这篇论文所提方法比当前最佳方法具有更高的早期检索效率。
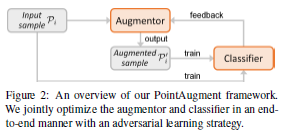
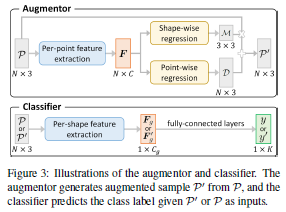
论文名称:PointAugment: an Auto-Augmentation Framework for Point Cloud Classification
作者:Li Ruihui /Li Xianzhi /Heng Pheng-Ann /Fu Chi-Wing
发表时间:2020/2/25
论文链接:https://paper.yanxishe.com/review/12686?from=leiphonecolumn_paperreview0324
推荐原因
这篇论文被CVPR 2020接收,要解决的是点云分类的问题。
这篇论文提出了一个名为PointAugment的点云分类框架,当训练分类网络时,该框架会自动优化和扩充点云样本以丰富数据多样性。与现有的2D图像自动增强方法不同,PointAugment具有样本感知功能,并采用对抗学习策略来共同优化增强器网络和分类网络,学习生成最适合分类器的增强样本。PointAugment根据形状分类器和点位移来构造可学习的点增强函数,并根据分类器的学习进度精心设计损失函数以采用增强样本。PointAugment在改善形状分类和检索中的有效性和鲁棒性得到了实验的验证。

雷锋网雷锋网雷锋网
相关文章:
今日 Paper | CVPR 2020 论文推荐:Social-STGCNN;无偏场景图生成;深度人脸识别;4D 关联图等

正在生成分享图...
 张璐
昨天 14:22
陈淑瑜
06月12日 17:36
陈淑瑜
06月12日 16:38
郑佳美
06月12日 14:28
张璐
昨天 14:22
陈淑瑜
06月12日 17:36
陈淑瑜
06月12日 16:38
郑佳美
06月12日 14:28