
CVPR 2020 | Social-STGCNN:一种用于行人轨迹预测的社会时空图卷积神经网络
CVPR 2020 | 基于有偏训练的无偏场景图生成
CVPR 2020 | 面向深度人脸识别的通用表征学习
CVPR 2020 | 使用多个摄像机的实时多人运动捕捉的4D关联图
CVPR 2020 | 一种基于U-Net的生成性对抗网络判别器
论文名称:Social-STGCNN: A Social Spatio-Temporal Graph Convolutional Neural Network for Human Trajectory Prediction
作者:Mohamed Abduallah /Qian Kun /Elhoseiny Mohamed /Claudel Christian
发表时间:2020/2/27
论文链接:https://arxiv.org/abs/2002.11927?from=leiphonecolumn_paperreview0323
推荐原因
这篇论文被CVPR 2020接收,考虑的是行人轨迹预测的问题。
行人轨迹不仅受行人本身影响,还与周围物体的相互作用有关。这篇论文提出了社会时空图卷积神经网络(Social Spatio-Temporal Graph Convolutional Neural Network,Social-STGCNN),将行人与周围物体的交互行为建模为图模型,并通过一个核函数将行人之间的社交互动嵌入邻接矩阵中。实验结果表明,与先前方法相比,Social-STGCNN的最终位移误差较现有技术提高了20%,参数减少了8.5倍,而推理速度提高了48倍。

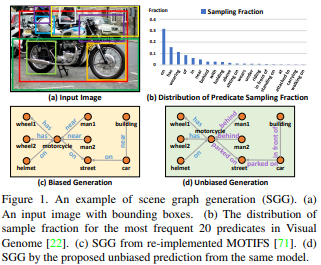
论文名称:Unbiased Scene Graph Generation from Biased Training
作者:Tang Kaihua /Niu Yulei /Huang Jianqiang /Shi Jiaxin /Zhang Hanwang
发表时间:2020/2/27
论文链接:https://arxiv.org/abs/2002.11949?from=leiphonecolumn_paperreview0323
推荐原因
这篇论文被CVPR 2020接收,要解决的是场景图生成的问题。
已有的场景图生成容易受有训练偏见的问题,例如将海滩上人类的步行、坐、躺等多样行为类型笼统分为海滩上的人类。这篇论文提出了一种新的基于因果推理的场景图生成的框架。首先建立因果图,然后使用该图进行传统的有偏训练,接着从训练图上得出反事实因果关系,以从不良偏置中推断出影响并将其消除。场景生成基准集Visual Genome上的实验表明这篇论文所提的方法与以前的最佳方法相比有显著改进。

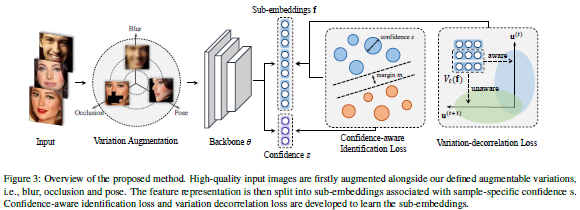
论文名称:Towards Universal Representation Learning for Deep Face Recognition
作者:Shi Yichun /Yu Xiang /Sohn Kihyuk /Chandraker Manmohan /Jain Anil K.
发表时间:2020/2/26
论文链接:https://arxiv.org/abs/2002.11841?from=leiphonecolumn_paperreview0323
推荐原因
这篇论文被CVPR 2020接收,提出了一种面向深度人脸识别的通用表征学习框架,可以处理给定训练数据中未发现的较大变化,而无需利用目标域知识。新框架首先将训练数据与一些有意义的语义变化(例如低分辨率、遮挡和头部姿势)一起合成。训练过程中将特征嵌入拆分为多个子嵌入,并为每个子嵌入关联不同的置信度值,以简化训练过程。通过对变化的分类损失和对抗性损失进行正则化,可进一步对子嵌入进行解相关。实验表明,新的框架在LFW和MegaFace等常规人脸识别数据集上均取得最佳性能,而在TinyFace和IJB-S等极端基准集上则明显优于对比算法。

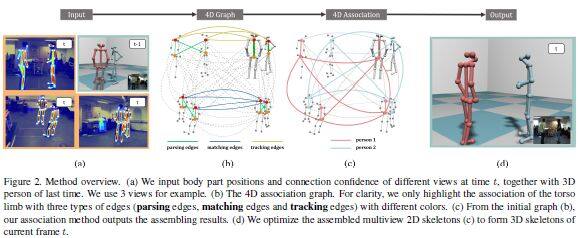
论文名称:4D Association Graph for Realtime Multi-person Motion Capture Using Multiple Video Cameras
作者:Zhang Yuxiang /An Liang /Yu Tao /Li Xiu /Li Kun /Liu Yebin
发表时间:2020/2/28
论文链接:https://arxiv.org/abs/2002.12625?from=leiphonecolumn_paperreview0323
推荐原因
这篇论文被CVPR 2020接收,提出了一种新的使用多视点视频输入的实时多人运动捕捉算法,首次将视图解析、跨视图匹配和时间跟踪整合到一个优化框架中,即得到一个4D关联图,该图可以同时平等地处理每个维度(图像空间、视点和时间)。为有效求解4D关联图,这篇论文进一步提出基于启发式搜索的4D肢束解析思想,然后通过提出束Kruskal算法对肢束进行组合。这个新算法可以在5人场景中使用5个摄像机,以30fps的速度运行实时在线运动捕捉系统。新算法不仅对噪声检测具有鲁棒性,还获得了高质量的在线姿态重建结果。在不使用高级外观信息的情况下,新算法优于当前最优方法。

论文名称:A U-Net Based Discriminator for Generative Adversarial Networks
作者:Schönfeld Edgar /Schiele Bernt /Khoreva Anna
发表时间:2020/2/28
论文链接:https://arxiv.org/abs/2002.12655?from=leiphonecolumn_paperreview0323
推荐原因
这篇论文被CVPR 2020接收,提出了一种基于U-Net的判别器架构,在保持合成图像的全局一致性的同时,向生成器提供详细的每像素反馈。在判别器的每像素响应支持下,这篇论文进一步提出一种基于CutMix数据增强的逐像素一致性正则化技术,鼓励U-Net判别器更多关注真实图像与伪图像之间的语义和结构变化,不仅改善了U-Net判别器的训练,还提高了生成样本的质量。新判别器在标准分布和图像质量指标方面改进了现有技术,使生成器能够合成具有变化结构、外观和详细程度的图像,并保持全局和局部真实感。与BigGAN基线模型相比,所提方法在FFHQ、CelebA和COCO-Animals数据集上平均提高了2.7个FID点。



雷锋网雷锋网雷锋网
相关文章:

正在生成分享图...
 张璐
昨天 14:22
陈淑瑜
06月12日 17:36
陈淑瑜
06月12日 16:38
郑佳美
06月12日 14:28
张璐
昨天 14:22
陈淑瑜
06月12日 17:36
陈淑瑜
06月12日 16:38
郑佳美
06月12日 14:28