雷锋网AI科技评论按:
社区发现(Community Detection)是网络科学领域中一个经久不衰的重要问题。
随着深度学习的发展,研究者们逐渐从传统的统计推断和谱聚类等方法中解放了出来。那么,深度学习时代的社区发现工作有哪些特点,研究者们遇到了哪些挑战,有哪些前景光明的研究方向呢?
近日,IJCAI 2020 上发表的一篇 Survey 文章,完整阐释了这一研究方向的方法、挑战和机遇。论文来自数据挖掘领域大牛 Philip S. Yu 团队。

论文标题:
Deep Learning for Community Detection: Progress, Challenges and Opportunities
社区发现(Community Detection)是网络科学领域中一个经久不衰的重要问题。随着深度学习的发展,研究者们逐渐从传统的统计推断和谱聚类方法中解放了出来。那么,深度学习时代的社区发现工作有哪些特点,研究者们遇到了哪些挑战,有哪些前景光明的研究方向呢?
网络中的社区指的是一组由节点以及与其相连的边紧密地形成的实体。社区发现旨在遵循「社区中的节点紧密相连,不同社区间的节点稀疏相连」的规则对实体集合进行聚类。包括谱聚类、统计推断在内的传统社区发现方法在处理高维图数据时存在计算速度的问题。因此,近年来,深度学习方法被广泛地应用。
在本文中,作者特别调研了社区发现的深度学习方法这一研究领域中的最新进展,并根据用到的深度神经网络、深度图嵌入、图神经网络对这些方法进行分类。由于目前深度学习的能力仍然不能满足处理复杂网络结构的需求,本文作者指出了当前该领域面临的挑战和研究机遇。
网络是有两种基本的实体(即节点和边)形成的。
根据图理论,「社区」是一种内部节点紧密相连的子图,它遵循以下特定的规则:
(1)社区内的节点紧密相连;
(2)不同社区中的节点稀疏相连。
人们也将社区看做一种聚类簇,其中相同社区内的节点可以共享共用的特性和/或扮演类似的角色。
这里根据 Radicchi 等人基于网络统计分析给出的定义展开讨论。根据节点在社区内部和外部的度,我们可以将社区分为两类:强社区和弱社区。 节点的「内部度」代表将该节点与同一个社区中其它节点连接起来的边数,节点的「外部度」则代表将该节点与属于其它社区的节点连接起来的边数。一个弱社区是其中的节点的内部度之和大于外部度之和的子图。一个强社区是其中每个节点的内部度都大于外部度的子图。针对社区的网络结构,本文采用了强社区的定义。
社区发现可以帮助我们理解网络内在的模式和功能。
在现实世界的应用中,社区将复杂系统中的信息聚集了起来。举例而言,
Chen、Yuan 等人发现在「蛋白质-蛋白质」交互(PPI)网络中,被聚合到社区中的蛋白质具有相似的生物学功能;
Chen 、Redner等人,在论文引用网络中,通过社区发现技术确定通过论文引用连接起来的课题的重要性、相互关联以及演变情况;
Zhang 等人,在企业网络中,通过研究离线的公司内部数据源以及在线的企业社交关系将雇员分组到不同的社区中;
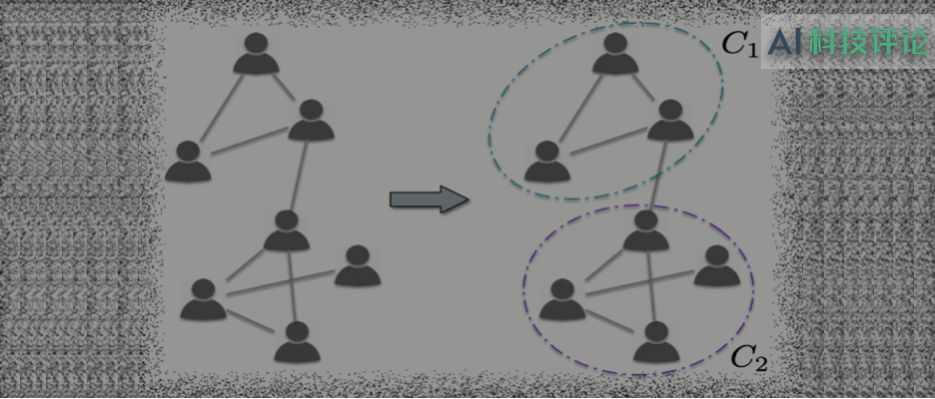
Yang 等人指出,在线社交网络中(例如 Twitter 和 Facebook)拥有共同的兴趣或朋友的用户可能来自同一个社区(如图 1 所示)。

图 1:社交网络中的社区发现示例。根据个体之间的紧密度,网络被划分为两个社区,即包含三个节点的社区 C_1 和包含四个节点的社区 C_2。
传统的社区发现方法大部分都是基于统计推断和机器学习发展出来的。例如, 在统计学领域非常具有代表性的社区发现方法「随机分块模型」(SBM)被广泛用于描述社区是如何形成的。然而,在处理当下的复杂数据及和社交场景时,这些传统的方法面临着许多问题。此外,在机器学习领域,发现社区的工作往往被看做一个图上的聚类问题。Ng 等人用特征向量(例如邻接矩阵和 Laplacian 矩阵)实现了将节点划分到社区中的谱聚类方法,然而这种方法在稀疏网络上的性能较差。
同时,对于预设的社区数目的要求也特别限制了依赖统计推断的模型的研发。在网络分析领域中,传统的方法并没有考虑到节点的属性,而这些属性描述了特征的丰富信息。此外,由于过高的计算复杂度,动态方法也很难被应用于大规模网络。总而言之,处理由图及其属性、大规模网络和动态环境形成的高维数据需要更强大的技术,从而同时兼顾高性能和计算速度。
深度学习使计算模型可以学习到具有多层次抽象的数据表征。许多计算模型和算法都需要对以网络结构形式存在的数据进行表征学习。深度学习技术在学习非线性特征时具有很大的优势。这一点在诸如计算机视觉、自然语言处理等领域中都取得了广泛的成功,在这些领域中数据有着内在的关系。在网络分析领域,深度学习可以有效地通过多层深度神经网络降低数据维度,从而完成社区发现、节点分类、链接预测等任务。
这里重点研究深度学习在社区发现任务中的应用的新研究趋势,Philip S. Yu等人的这篇综述贡献有:
(1)分析了将深度学习方法用于社区发现的优势;
(2)从技术的视角,总结了目前最先进的研究,并对其进行分类;
(3)讨论了仍然存在的挑战,并指出了具有前景的未来工作的机遇。
据AI科技评论所知,这篇综述也是首次全面回顾深度学习在社区发现中的应用,对研究人员和技术专家理解深度学习和社交网络领域的发展趋势有着巨大帮助。

图 2:社区发现之深度学习:进步、挑战和机遇。
简单来说,社区发现,即从网络 G 中发现社区 C。
这里提到的网络是一种特殊的图,它对现实世界中的系统(例如,互联网、学术合作网络以及社交群组)中的复杂关系进行了抽象。在这里,网络的概念主要强调的是其拓扑结构。
定义 1(网络 G)
基于图理论,有权网络可以被表征为 G=(V,E,W),而无权网络可以被表征为 G=(V,E),其中 V 和 E 分别代表节点的集合和边的集合,W 代表 E 相应的权值。每条边通过权值描述连接强度或者容量。我们可以将无权图的 W 视为1,将其从图 G 中去除。
子图 g⊆G 是对于图的一种划分,它保持了原始的网络结构。子图的划分遵循预先定义好的规则。根据不同的规则可能得到不同形式的子图。社区是一种表征真实社交现象的子图;也就是说,在群组中存在一组具有紧密关系的对象。这里遵循由 Radicchi 定义的强社区的概念。
定义 2(社区 C)
社区是一组网络中相互联系的子图。社区中的节点具有密集的连接,而不同社区之间的节点具有稀疏的连接。根据一种将节点聚类到不同群组中的网络划分方法给出一个社区 C_i,我们得到 C={C_1,C_2,...,C_k},其中 k 代表可以从原始网络中被划分出的社区数。被聚合到社区 C_i 中的节点 v 满足:v 到社区内每个节点的内部度大于其外部度。
与其他机器学习方法相比,深度学习的明显优势是它能够将高维数据编码到一个新的特征表征中。通过使用以图结构的形式组织的数据表征节点之间的联系,许多深度学习方法都可以学习到节点、邻域以及子图的模式。在多数现实场景中,数据缺乏节点标签信息和关于社区的先验信息,而深度学习在无监督学习的任务中体现出了优势。除了简单地利用网络拓扑来发现社区之外,一些方法还将语义描述作为数据中的节点属性加以研究。在传统社区发现方法中,这类方法主要基于邻接矩阵和节点属性矩阵。然而,深度学习可以构建更有效的节点属性和社区结构表征。
因此,深度学习填平了传统社区发现方法中存在的关键短板。为了实现这一目标,近年来的工作指出了一些具有前景的研究方向:将深度学习模型应用于社区发现,以及基于社区的特性修改深度学习模型。将深度学习应用于社区发现的前景可以被表述为:
(1)通过深度学习模型提升传统社区发现方法的性能;
(2)从对于深度学习至关重要的特征维度上引入更多的信息;
(3)从网络实体的拓扑和属性入手,同时提升模型的学习性能和鲁棒性;
(4)现在可以更好地从复杂的相关结构中对大规模网络进行检测。
为了对近年来将深度学习用于社区发现的研究进展进行概述,Philip等人从技术的角度总结了现有的方法。具体而言,他们首先对具有影响力的社区发现深度学习方法进行了分类。在每一类中,他们概述了框架、模型以及算法的技术贡献。
为了研究近年来被应用于社区发现的深度学习方法,图 2 描述了相关深度学习方法的详细分类情况,并相应地附上了总结出来的挑战。本章将从基于深度神经网络、基于深度图嵌入、以及基于图神经网络的社区发现方法三个方面展开叙述。
4.1 基于深度神经网络的社区发现
深度神经网络在对复杂的关系进行建模和发现的任务中具有天然的优势。考虑到现有的深度神经网络模型在社区发现领域的流形程度,作者选取了基于卷积神经网络(CNN)、基于自编码器、基于生成对抗网络(GAN)的社区发现方法进行调研。
基于 CNN 的社区发现
CNN 的关键组件包含卷积操作和对卷积层结果的最大池化操作。卷积操作利用卷积核降低计算开销。随后,最大池化操作被用于特征提取,这保证了 CNN 的鲁棒性。
得益于 CNN 的发展,Xin 等人设计了一种用于社区发现的新型 CNN,并提出了一种用于拓扑结构不完整的网络的有监督算法。由于社区发现被广泛看做一种无监督聚类任务,科研人员对基于无监督 CNN 的社区发现进行了研究。人们研发出了在 CNN 框架下的系数矩阵卷积,从而专门进行对高度稀疏的邻接矩阵的表征。
基于自编码器的社区发现
栈式自编码器是一种深度学习模型,它在社区发现任务中表现出了强大的性能,可以表征网络矩阵的非线性特征。研究者们发现自编码器和谱聚类在谱矩阵的低维近似方面有相似的框架,并受此启发将自编码器引入了社区发现领域。此后,Cao 等人提出了一种将网络拓扑和节点属性相结合的栈式自编码器,它提升了深度神经网络隐层的泛化能力。为了进一步解决网络拓扑和节点属性之间的匹配问题,Cao 等人通过引入一个控制这种匹配的折中的自适应参数,研发了一种带有图正则化的自编码器方法。
着眼于网络拓扑,Xie 等人提出在深度自编码器中对邻接矩阵进行变换,从而有效地学到节点相似度。同时,Bhatia 和 Rani 提出的自编码器通过对随机游走序列建模学习节点的结构,他们通过优化社区结构的模块度对这种序列进行调优。
为了避免预设社团的数量,Bhatia 和 Rani 提出了一种层级栈式自编码器,他们找出种子节点,基于网络结构有效地将其它节点加入到社区中。此后,该领域的研究旨在自适应地学习而不是预定义社区结构。Choong 等人提出的方法大大地提升了训练损失验证阶段的计算效率。这种自动选择机制保证了模型基于社区标准分配节点。
Xu 等人将包含具有正负号连接的网络成为有符号网络(signed network)。为了处理边上的有符号信息,Shen 和 Chung 提出了一种半监督的栈式自编码器,它可以重构邻接矩阵,为进一步的深度学习网络嵌入的学习表征有符号网络。
基于生成对抗网络(GAN)的社区发现
GAN 包含两种相互竞争的深度神经网络,因此它可以迅速调整训练精度。典型的 GAN 是以无监督方式运行的,它们生成与训练集中的数据具有相同统计特征的新数据。对于网络数据来说,GAN 模型适用于无标签的数据集和序列化的网络划分。
Yang 和 Leskovec 等人基于对抗性机制,提出了社区隶属关系图模型(AGM)。AGM 基于「节点-社区」成员隶属关系(node membership)的思想对重叠的社区中的节点进行编码。每个社区都有一个单一的概率,使得社区结构可以在 GAN 中进行。Jia 等人通过将这种模型与 GAN 相结合研发了一种新型的框架,它根据具有中间项(即隶属图中的「节点-社区」成员隶属关系)进行社区发现。
4.2 基于深度图嵌入的社区发现
深度图嵌入是一种将网络中的节点映射到一个低维向量空间中的技术。它将尽可能多的结构信息保存到表征中。通过图嵌入,基于网络分析的机器学习任务(例如链接预测、节点分类和节点聚类)可以利用表征的潜在特征,这样节省了主要由网络搜索引起的计算开销。对于社区发现任务来说,基于节点表征的图嵌入的输出支持聚类的任务(例如通过 k-means 聚类)。
基于深度非负矩阵分解的社区发现
非负矩阵分解(NMF)是一类将矩阵分解为两个矩阵的算法,它具有如下性质:三个矩阵都没有负的特征值。NMF 自动地对输入数据的列进行聚类,通过训练阶段的误差函数,使原始矩阵和两个分解出的矩阵之间的近似误差最小。
Ye 等人提出了一种用于社区发现的深度 NMF 模型,其中深度学习架构可以促进 NMF 学习原始网络结构和社区结构之间的层次化映射。在某些情况下,社区发现的工作需要与对带有属性的内容的语义理解同时进行。为此,研究人员以一种带属性的图的形式表征网络,这种图同时包含了网络结构和节点的属性。Li 等人特别针对带属性图的社区发现任务提出了一种嵌入方法,它将带有属性的社区发现看做一个 NMF 优化问题。为了使算法收敛,他们设计了一套可计算的迭代更新规则。
基于深度稀疏滤波的社区发现
邻接矩阵反映出了网络的稀疏性。嵌入对输入的成对关系进行编码,从而避免在稀疏矩阵上进行搜索。稀疏滤波(SF)是一种有效的深度特征学习算法,它只用到了一个超参数,但可以处理高维输入。SF 的关键模块是针对 L2 正则化后的特征的稀疏性设计的简单代价函数。对于网络(尤其是在大型网络中)的社区发现,Xie 等人基于深度稀疏滤波提出了一种高效的网络表征方法。他们通过一种无监督的深度学习算法划分网络,从而提取网络特征。
基于社区嵌入的社区发现
传统意义上,图嵌入重点关注单个的节点。Cavallari 等人研究了另一种重要的、但是鲜有人探索过的图嵌入情况,他们重点关注对社区的嵌入。他们认为这种新的重要策略有益于社区发现任务。具体而言,社区嵌入的目标是在低维空间中学习一种社区的节点分布。我们可以通过过渡性(transitional)的图嵌入方法使用这种新的节点分布,从而很好地保留网络结构,这反过来可以提升社区发现的性能。此外,Tu 等人提出了一种新的图嵌入模型,它同时探测每个节点的社区分布,并且学习节点和社区的嵌入。
网络中的社区实际上反映了同一个社区中相似的观点、行为等高阶近似信息。Zhang 等人提出了一种保留社区信息的社交网络嵌入方法来学习网络表征。他们提出的这种方法在社区检测任务中体现出了性能的优越性。
4.3 基于图神经网络的社区发现
近年来,图神经网络(GNN)的迅猛发展表明了图挖掘和深度学习技术融合的趋势。基于 GNN 的社区发现被用于利用图神经网络对网络上的复杂关系进行建模,并捕获这种关系。例如,Chen 等人提出的有监督社区发现 GNN 引入了一种非回溯的运算符,来定义边的邻接性。这种方法可以提升学习性能。对于 GNN 来说,运算符的选择非常方便。
图卷积网络(GCN)是基于 CNN 研发的,它继承了快速学习的能力。面对图输入数据,GCN 展现出了非常好的性能。GCN 带来的巨大提升在于整合了考虑网络中实体概率分布的概率模型。例如,Jin 等人通过马尔科夫随机场解决了包含语义信息的带属性网络中的半监督社区发现问题。Shchur 和 Gunnemann 将「伯努利-泊松」概率模型整合到 GCN 中,用于重叠社区发现问题。通过这种方法,卷积层可以识别复杂的网络模式。
近年来(尤其是近 5 年来),用于社区发现的深度学习技术迅速发展。由于对现实世界具有重大的影响,这一领域持续受到研究人员的关注。尽管取得了令人欣喜的成果,在将深度学习应用于社区发现的领域中,仍然有一些挑战有待被更好地解决。下面,本文将总结这些挑战和机遇。
挑战 1:社区数未知
长久以来,由于社区数未知而引发的挑战始终没有得到很好的解决。在机器学习领域中,社区发现经常被表示为一种无监督聚类任务。总现实世界的网络中提取出的研究数据大多是没有标签的。因此,我们很难获取有关社区数的先验知识。此外,大多数现有的深度学习社区发现方法(尤其是深度图嵌入),通过评估潜在特征空间中的节点相似度获取分类节点。然而,在后续的聚类算法中,聚类的目标数量仍然需要被事先定义。
机遇:对于这一挑战,一个直接的解决方案是通过分析网络拓扑确定社区的数量,并将其整合到深度学习模型中。Bhatia 和 Rani 等人遵循这一思想,采用基于随机游走的定制化 PageRank 算法,通过将图重构到一种线性的形式进行社区发现,并通过模块化的优化方法来应用调优。但是这些方法并不能保证网络中的每个节点可以被分配到特定的社区中。因此,我们需要为社区发现任务涉及新的模型,从而避免在分配社区的过程中漏掉某些节点。
挑战 2:网络层次
网络层次反映了分层的网络结构,它将位于独立的层上的多个群组连接了起来,从而形成一个更加复杂的网络。而每一层都专注于特定的功能。对于多层网络,用于社区发现的深度学习技术必须实现对于两种层次上的表征的提取。而且他们将面临多层网络固有的挑战,这包括不同的关系类型以及不同层中不同的稀疏程度。
机遇:为了区分不同种类的连接,Song 和 Thiagarajan 提出了一种具有特殊子图设计的多层 DeepWalk 模型,从而保存了层次化的结构。但是他们并没有同时优化可以用于所有层的公用表征以及保留了特定层网络结构的局部表征。他们的目的是利用不同层之间的依赖,而实际上这种依赖关系经常被破坏。此外,对于新的设计来说,还应该考虑与层数增加有关的可伸缩性问题。因此,在研发用于具有网络层次的社区发现的深度学习方法的问题上,我们还有很长的路要走。
挑战 3:网络异质性
网络的异质性指的是网络中实体类型的显著差异,而各种各样的节点集合和它们之间复杂的联系形成了异质网络。因此,我们应该通过不同于同质网络的方式研究异质网络中的社区发现。在应用和研发深度学习模型和算法时,应该解决异质网络实体上的概率分布的差异。
机遇:大多数之前的深度学习方法并不是基于网络异质性研发的。Change 等人设计了一种非线性嵌入函数,它被用于捕获异质组件之间的交互。因此,未来在异质网络上至少存在两个方面的研究机遇:(1)异质网络表征的深度图嵌入学习模型以及相关的支撑算法;(2)采用新型训练过程的特定深度学习模型,旨在学习隐藏层中的异构图属性。
挑战 4:边上带符号的信息
许多现实世界中的网络具有边上的符号信息(即正关系或负关系)。在有符号网络的环境下,用于社区发现的深度学习方法面临的挑战是:通过不同的符号信息表示的节点之间的联系应该以不同的方式对待。
机遇:一种可能的解决方案是,通过设计一种随机游走过程引入正关系边和负关系边。Hu 等人遵循这一思路,基于词嵌入技术研发了一种稀疏图嵌入模型。但是,他们的方法在一些小型的真实世界中的有符号网络中的性能要差于作为对比基线的谱方法。另一种的可能的解决方案是重建一个有符号网络的邻接矩阵表征。然而,这又面临着另外一个问题:现实世界中的绝大部分邻接连接是正关系。Shen 和 Chung 施加了更大的惩罚,使他们的栈式自编码器模型更加关注重建稀缺的负边而不是丰富的正边。然而,在大多数情况下,我们并不能获取关于大量节点的社区分配信息。因此,在有符号网络中,社区发现的高效的无监督方法仍然有待探索。
挑战 5:社区嵌入
社区嵌入是一个新兴的研究领域,这种方法将对社区而不是每个独立的节点进行嵌入。社区嵌入重点关注对社区进行感知的高阶近似而不是在节点邻居之间的 1 阶或 2 阶近似。未来,社区嵌入研究面临的挑战有:(1)高昂的计算开销;(2)节点和社区结构之间的关系评估;(3)应用深度学习模型时发生的其它问题,例如社区之间的分部漂移。
机遇:设想有一种智能的方法通过自动选择针对节点和/或社区的表征模块来支撑社区嵌入。为此,Philip等人建议从以下研究目标入手:(1)如何将社区嵌入整合到一个深度学习模型中?(2)如何为了「计算地更快」这样的目标直接嵌入社区结构?(3)如何优化整合好的深度社区发现学习模型中的超参数?
挑战 6:网络的动态性
网络的动态性主要包含两种情况:网络拓扑的变化,以及在固定拓扑上的属性的变化。拓扑的变化会引起社区的演化。例如,添加或删除一个节点会影响全局的网络连接,因此它也会改变社区结构。对于静态网络来说,深度网络社区发现学习模型在面对每个网络的快照时,需要重新训练,这里面包含一些重复的工作。对于静态网络中的时序属性,技术上的挑战在于对于流数据的深度特征提取,这些流数据的概率分布和属性随时都会变化,它们引入图数据作为深度学习模型输入的另一部分。
机遇:针对时间和空间维度上的动态特性,人们还没有研发用于社区发现的深度学习模型。未来的研究方向包括:(1)发现并识别社区间的空间变化;(2)学习深度模式,它同时对时序特征和社区结构信息进行嵌入;(3)为社区发现任务研发一种统一的深度学习方法,它可以同时处理空间和时间特征。
挑战 7:大规模网络
大规模网络指的是拥有数以百万计的节点和边、大规模结构化模式以及高度动态性的大型网络。因此,大规模网络有其固有的规模特性(例如,社交网络中与规模无关的特性,节点度的米率分布特性),这些特性会影响社区发现任务中的聚类系数。此外,通过分解后的有关高维邻接关系的近似度度量,研究人员将分布式计算应用于可扩展的学习,同时他们也面临着鲁棒的学习控制和协作计算的问题。不断变化的网络拓扑进一步增加了近似度估计的难度。总而言之,大规模网络中的社区发现设计上述所有提到的挑战,以及可扩展学习方面的挑战。
机遇:大规模网络(例如,Facebook 和 Twitter)不仅提出了挑战,也催生了设计更先进的深度学习方法的机遇。为了充分利用大规模网络中的丰富信息,社区上的聚类任务更需要具有较低的计算复杂度并具有灵活性的新型无监督算法。深度学习中用到的关键数据降维方法(即矩阵低秩近似)并不适用于大规模网络,它在分布式计算场景下的计算开销也是很高昂的。因此,人们急需新型的深度学习框架、模型和算法。研发应用于大规模网络的深度学习方法需要通过精度和速度来评估,这种评估方式可能是最大的挑战。
如今,我们生活在各种各样的网络中。发现这些网络的内在功能和特征有助于我们全面地理解周围的环境(尤其是在社交网络中)。
社区还原了描述社会现象的复杂关系。传统的社区发现方法曾经依赖的是统计推断和机器学习(谱聚类)。然而,深度学习的发展极大地提升了社区发现方法的计算性能,用于社区发现的深度学习方法近五年来被广泛地研究。
在这篇综述文章中,Philip 等人全方位地回顾了模型和算法研发方面相应的技术趋势,并针对基于深度学习领域社区发现进展做了详细的阐述。
最为重要的是,这篇综述还指出了将深度学习用于社区发现任务时存在的七个重大挑战,这在一定程度上将为下一代社区发现研究指明方向。雷锋网雷锋网雷锋网

正在生成分享图...
 周舟
周舟