上个月,我尝试构建一个 reddit 评论机器人,通过结合两个预先训练的深度学习模型 GPT-2 和 BERT 生成自然语言回复。在这里我想一步一步地介绍一下我的工作,这样其他人就可以用我所建立的东西来工作了。如果愿意,可以直接跳转到项目代码:https://github.com/lots-of-things/gpt2-bert-reddit-bot 。这项工作还参考了以下内容:https://colab.research.google.com/drive/1VLG8e7YSEwypxU-noRNhsv5dW4NfTGce;https://colab.research.google.com/github/google-research/bert/blob/master/predicting_movie_reviews_with_bert_on_tf_hub.ipynb
模型概述
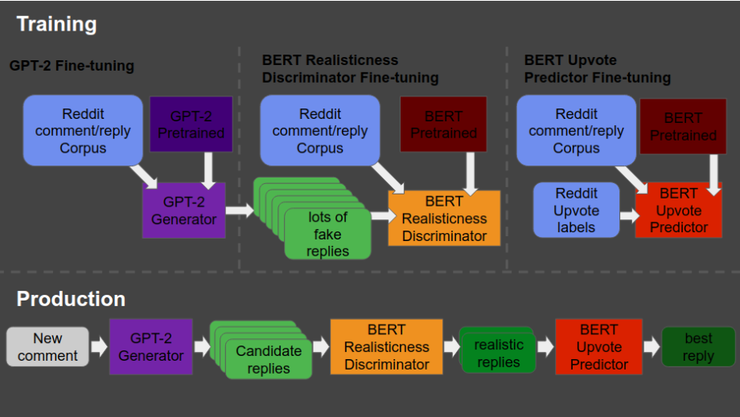
在讨论细节之前,我想对整个过程做一个概述。这个流程图显示了我需要训练的 3 个模型,以及将模型连接在一起以生成输出的过程。

这里有很多步骤,但我希望它们不要太混乱。以下是我将在这篇文章中解释的步骤。
步骤 0:从你最喜欢的 reddit 文章中获取一些 reddit 评论数据,并将其格式化为类似「comment[SEP]reply」的字符串
步骤 1:微调 GPT-2 以生成格式为「comment[SEP]reply」的 reddit 文本
步骤 2:微调两个 BERT 分类器:
a: 区分真实回复和 GPT-2 生成的回复
b: 预测评论将获得多少次支持
步骤 3:使用 praw 下载当前评论
步骤 4:使用微调的 GPT2 为每个评论生成多个回复
步骤 5:将生成的回复传递给两个 BERT 模型,以生成对真实性和投票数的预测
步骤 6:使用一些标准来选择要提交的回复
步骤 7:使用 praw 提交所选评论
步骤 8:享受成果!
获取大量 reddit 评论数据
与任何机器学习项目一样,只有获得用于训练模型的数据,才能启动项目。
我用来微调模型的数据来自之前检索到的 reddit 评论大型数据库:https://bigquery.cloud.google.com/dataset/fh-bigquery:reddit_comments?pli=1 。有一个正在进行的项目(https://www.reddit.com/r/bigquery/wiki/datasets ),它在 web 上搜索许多站点,并将它们存储在一堆 Google BigQuery 表中。对我来说,我很惊讶竟然找不到一个关于如此大的项目的中心页面,但我用了几个 reddit 和 medium 帖子来拼凑我需要的查询格式。
首先,我下载了一堆评论和回复信息,分别是「写作」、「科幻」、「科幻小说」、「机器学习」、「哲学」、「COGSICI」、「神经学」和「未来学」。此查询用于从 bigquery 中提取特定年份和月份({ym})的注释。
SELECT s.subreddit as subreddit,
s.selftext as submission, a.body AS comment, b.body as reply,
s.score as submission_score, a.score as comment_score, b.score as reply_score,
s.author as submission_author, a.author as comment_author, b.author as reply_author
FROM `fh-bigquery.reddit_comments.{ym}` a
LEFT JOIN `fh-bigquery.reddit_comments.{ym}` b
ON CONCAT('t1_',a.id) = b.parent_id
LEFT JOIN `fh-bigquery.reddit_posts.{ym}` s
ON CONCAT('t3_',s.id) = a.parent_id
where b.body is not null
and s.selftext is not null and s.selftext != ''
and b.author != s.author
and b.author != a.author
and s.subreddit IN ('writing',
'scifi',
'sciencefiction',
'MachineLearning',
'philosophy',
'cogsci',
'neuro',
'Futurology')
我使用 bigquery python API 自动生成查询,以便下载 2017 年和 2018 年的几个月的数据。这个脚本在我需要的时间段内迭代,并将它们下载到 raw_data/ 文件夹中的本地磁盘。
最后,我希望能够给 GPT-2 网络加上一条评论并生成一个回复。为此,我需要重新格式化数据,使其包含由特殊 [SEP] 字符串分隔的两部分,以便让算法分清每个部分。每行训练数据看起来是如下的样子。
"a bunch of primary comment text [SEP] all of the reply text”
在我用这种格式训练模型之后,我可以给训练模型一个字符串,比如「一些新的主要评论文本」,它将开始根据训练数据生成它认为最适合的剩余的「一些新回复」。下面我将更详细地解释如何将此类数据输入 GPT-2 微调脚本。现在,你可以使用此脚本将数据转换为 GPT-2 微调所需的格式,并将其保存为 gpt2_finetune.csv。
微调 GPT-2 并为 reddit 生成文本
使用 GPT-2 的主要优势在于,它已经在互联网上数百万页文本的海量数据集上进行了预训练。然而,如果你直接使用 GPT-2,你最终生成的文本会看起来像你在互联网上找到的任何东西。有时它会生成一篇新闻文章,有时它会生成一个烹饪博客菜谱,有时它会生成一个充满愤怒情绪的 facebook 帖子。你没有太多的控制权,因此,你将无法真正使用它来有效地生成 reddit 评论。
为了克服这个问题,我需要「微调」预先训练的模型。微调意味着采用一个已经在大数据集上训练过的模型,然后只使用你想要在其上使用的特定类型的数据继续对它进行训练。这个过程(有点神奇地)允许你从大的预训练模型中获取大量关于语言的一般信息,并用所有关于你正试图生成的确切输出格式的特定信息对其进行调整。
微调是一个标准的过程,但并不是很容易做到。我不是一个深度学习专家,但幸运的是,对我来说,一个非常优秀的专家已经建立了一些非常简单的打包好的实用程序,它就是 gpt-2-simple,可以用于微调 gpt-2,是不是很简单?!
最棒的是,gpt-2-simple 的作者甚至建立了一个经过微调的 Google Colab notebook。Google Colab 是一个令人惊叹的免费资源,可以让你在 Google GPU 服务器上运行 python jupyter notebook。这项资源完全公开,因此我正式成为了谷歌的终身粉丝。
你可以跟随教程(https://colab.research.google.com/drive/1VLG8e7YSEwypxU-noRNhsv5dW4NfTGce )学习如何使用 GPT-2-simple 微调 GPT-2 模型。对于我的用例,我把所有的代码压缩并重新格式化了一点,以生成自己的 gpt-2 notebook(https://colab.research.google.com/drive/1VyOU81rsPsP_8WSKq-VZfB8TcMkPszG- ),它运行在我在上一步生成的 gpt2_finetune.csv 文件上。和在原始教程中一样,你需要授予笔记本从 Google 驱动器读写的权限,然后将模型保存到 Google 驱动器中,以便从以后的脚本重新加载。
用于伪检测和上投票预测的训练BERT模型
即使经过微调,这个模型的输出也可能会相当怪异。为了提高回复的质量,我修改了 GAN 的概念,创建了另一个元模型,这个模型能够找出所有奇怪的回复。因此,我使用 GPT-2 为每条评论生成 10+ 个候选回复,然后使用另一个模型筛选出我能发布的最佳回复。
为了确定最佳方案,我实际上想做两件事:
过滤掉不切实际的回复
对于具有现实性的回答,选择一个我认为最有说服力的
因此,为了做到这一点,我必须训练两个分类器,一个是预测真实回复的概率,另一个是预测高分回复的概率。有很多方法可以执行这个预测任务,但是最近为这类问题构建的最成功的语言模型之一是另一种深度学习架构,称为 Transformers 或 BERT 的双向编码器表示。使用这个模型的一个很大的好处是,与 GPT-2 类似,研究人员已经在我永远无法获得的超大型数据集上预先训练了网络。
同样,我不是使用深度学习基础设施最厉害的专家,但幸运的是,其他优秀的 tensorflowhub 专家编写了一个 GoogleColab 教程(https://colab.research.google.com/github/google-research/bert/blob/master/predicting_movie_reviews_with_bert_on_tf_hub.ipynb ),使用预先训练的 BERT 网络对文本分类器模型进行微调。所以我所要做的就是把两者结合起来。
在下一节中,我将介绍微调和一些模型评估,但是如果你想快速启动而不想自己费心微调,可以从这里(https://drive.google.com/open?id=1GmGNqihV0nCQ6evLBmopOhjups_RESv- )、这里(https://drive.google.com/open?id=1-Bov5PtPrP2DvFw4yD-lxp2wTjGw0bwB )和这里(https://drive.google.com/file/d/1DTfYUxXEz80S0baCb4xPSrzx85F0FVTP/view?usp=sharing )下载三个微调的模型。
BERT 鉴别器性能
评估现实性的模型的训练就和在传统的 GAN 中一样。我让另一个 Colab notebook 生成了成千上万的虚假评论,然后创建了一个数据集,将我的虚假评论与成千上万的真实评论混在一起。然后,我把这个数据集输入一个 BERT 现实性微调的 notebook 进行训练和评估。该模型实际上具有惊人的区分真假评论的能力。
BERT 现实性模型度量
'auc': 0.9933777,
'eval_accuracy': 0.9986961,
'f1_score': 0.99929225,
'false_negatives': 3.0,
'false_positives': 11.0,
'precision': 0.9988883,
'recall': 0.99969655,
'true_negatives': 839.0,
'true_positives': 9884.0
接下来,生成器创建的每个回复都可以通过这个 BERT 鉴别器运行,根据其真实性会得到从 0 到 1 的分数。然后我只过滤返回最具有真实性的评论。
为了预测一个回复将获得多少次支持,我以类似的方式(https://drive.google.com/open?id=1vXJjQbBZZ0Jo-LvcwRaNzCSAgAVem1cC )构建了另一个模型。这一次,这个模型只是在一个数据集上训练,这个数据集包含了一堆真实的 reddit 评论,用来预测他们实际获得了多少投票。
该模型还具有令人惊讶的高预测精度。下面这个 ROC 曲线表明,我们可以得到很多正确的真阳性,而不会有太多的假阳性。关于真阳性和假阳性的含义,请参阅本文:https://developers.google.com/machine-learning/crash-course/classification/true-false-positive-negative 。

基于BERT 的支持票预测的 ROC 曲线
在模型交叉验证性能的支持下,我很高兴将它连接到一个实时评论系统,并开始发布我的机器人的想法!
用PRAW拉实时评论
尽管我可以使用 bigquery 上的数据生成训练集,但大多数数据实际上都是几个月前的。在社交媒体网站上回复几个月前的评论是一件非常不正常的事情,因此能够以某种方式从 reddit 上获取最新的数据非常重要。
幸运的是,我可以使用 praw 库和下面的代码片段,从几个我认为会产生一些有趣响应的 reddit 中的前 5 个「上升」帖子中获取所有评论。
for subreddit_name in ['sciencefiction',
'artificial',
'scifi',
'BurningMan',
'writing',
'MachineLearning',
'randonauts']:
subreddit = reddit.subreddit(subreddit_name)
for h in subreddit.rising(limit=5):
我可以在生成器和鉴别器中运行每条评论以生成一个回复。
运行生成器和鉴别器
最后,我只需要构建一些东西来重新加载所有经过微调的模型,并通过它们传递新的 reddit 评论来获得回复。在理想的情况下,我会在一个脚本中运行 GPT-2 和 BERT 模型。不幸的是,设计人员在实现 gpt2-simple 包的过程中有一个怪癖,使得在同一个环境中无法实例化两个计算图。
所以,我自己运行了一个 GPT-2 生成器 notebook(https://drive.google.com/open?id=1Z-sXQUsC7kHfLVQSpluTR-SqnBavh9qC ),下载最新的评论,生成一批候选回复,并将它们存储在我的 Google 驱动器上的 csv 文件中。然后,我在一个单独的 BERT 鉴别器 notebook(https://drive.google.com/open?id=1mWRwK1pY34joZul5gBeMortfTu8M9OPC )中重新加载了候选的回复,选择最好的回复并将其提交回 reddit。
你可以在项目的 github repo(https://github.com/lots-of-things/gpt2-bert-reddit-bot )或 Google Drive文件夹(https://drive.google.com/open?id=1by97qt6TBpi_o644uKnYmQE5AJB1ybMK )中查看整个工作流。如果你认为事情可以解释得更清楚,或者你发现了错误,请将问题提交给项目。
最后一步:享受成果
我在 tupperware party 的 reddit 帐户下提交了所有回复(希望不会因为商标问题而被关闭)。你可以在这里(https://www.bonkerfield.org/2020/02/combining-gpt-2-and-bert/#replies )查看模型输出的一些亮点,或者查看注释的完整列表,以检查系统输出的所有内容。我也在 Google Drive 上共享了一个文件夹(https://drive.google.com/drive/folders/1a2MhIqL6jvyJ-3bGCXAweLbYtNXSUei7?usp=sharing ),其中包含了所有的候选答案以及 BERT 模型中的分数。
最后,我知道在创作这样的作品时,肯定有一些伦理上的考虑。所以,请尽量负责任地使用这个工具。
via:https://www.bonkerfield.org/2020/02/reddit-bot-gpt2-bert/
雷锋网雷锋网雷锋网

正在生成分享图...
 nebula
nebula