JAX 的表现出乎所有人的意料,在极端情况下,最大性能可提高 20 倍。由于 JAX 的 JIT 编译开销,Numpy 在少样本、少量链的情况下会胜出。我报告了 tensorflow probability (TFP) 的结果,但请记住,这种比较是不公平的,因为它实现的随机游走 metroplis 比我们的包含更多的功能。
重现结果所需的代码可以在这里找到。使代码运行得更快的技巧值得学习。
矢量化 MCMC
Colin Carroll 最近发布了一篇有趣的博文,使用 Numpy 和随机游走 metropolis 算法 (RWMH) 的矢量化版本来生成大量的样本,同时运行多个链以便对算法的收敛性进行后验检验。这通常是通过在多线程机器上每个线程运行一个链来实现的,在 Python 中使用 joblib 或自定义后端。这么做很麻烦,但它能完成任务。
Colin 的 文章让我感到非常兴奋,因为我可以在几乎不增加成本的情况下,同时对成千上万的链进行取样。他在文章中详细介绍了几个这一方法的应用,但我有一种直觉,它可以完成更多的事情。
大约在同一时间,我偶然发现了 JAX。JAX 在概率编程语言环境中似乎很有趣,原因如下:
在大多数情况下,它完全可以替代 Numpy;
Autodiff 很简单;
它的正向微分模式使得计算高阶导数变得容易;
JAX 使用 XLA 执行 JIT 编译,即使在 CPU 上也可以加速代码的运行;
使用 GPU 和 TPU 非常简单;
这是一个偏好问题,但它更倾向于函数式编程。
在开始使用 JAX 实现一个框架之前,我想做一些基准测试,以了解我要注册的是什么。这里我将进行比较:
Numpy
Jax
Tensorflow Probability (TFP)
XLA 编译的 Tensorflow Probability
关于基准测试
在给出结果之前,首先需要声明的是:
报告的时间是在我的笔记本电脑上运行 10 次的平均值,除了终端打开外,没有任何其它操作。除了编译后的 JAX 运行外,所有运行的时间都是使用 hyperfine 命令行工具测量的。
我的代码可能不是最优的,对于 TFP 来说尤其如此。
实验是在 CPU 上进行的。JAX 和 TFP 可以运行在 GPU/TPU 上,所以可以期待额外的加速。
对于 Numpy 和 JAX 来说,采样器是一个生成器,样本不保存在内存中但对 TFP 来说并非如此,因此在大型实验期间,计算机会耗尽内存。如果 TFP 没有在堆栈上预先分配内存,不断地分配内存也会影响性能。
在概率编程中重要的度量是每秒有效采样的数量,而不是每秒采样数量,前者后者更像是你使用的算法。这个基准测试仍然可以很好地反映不同框架的原始性能。
设置和结果
我在对一个含有 4 个分量的任意高斯混合样本进行采样。使用 Numpy:
import numpy as np
from scipy.stats import norm
from scipy.special import logsumexp
def mixture_logpdf(x):
loc = np.array([[-2, 0, 3.2, 2.5]]).T
scale = np.array([[1.2, 1, 5, 2.8]]).T
weights = np.array([[0.2, 0.3, 0.1, 0.4]]).T
log_probs = norm(loc, scale).logpdf(x)
return -logsumexp(np.log(weights) - log_probs, axis=0)
Numpy
Colin Carroll 的 MiniMC 是我见过的最简单、最易读的大都市随机游走 Metropolis 和 Hamiltonian Monte Carlo 的实现。我的 Numpy 实现是他的一个迭代:
import numpy as np
def rw_metropolis_sampler(logpdf, initial_position):
position = initial_position
log_prob = logpdf(initial_position)
yield position
while True:
move_proposals = np.random.normal(0, 0.1, size=initial_position.shape)
proposal = position + move_proposals
proposal_log_prob = logpdf(proposal)
log_uniform = np.log(np.random.rand(initial_position.shape[0], initial_position.shape[1]))
do_accept = log_uniform < proposal_log_prob - log_prob
position = np.where(do_accept, proposal, position)
log_prob = np.where(do_accept, proposal_log_prob, log_prob)
yield position
JAX
JAX 的实现与 Numpy 非常相似:
from functools import partial
import jax
import jax.numpy as np
@partial(jax.jit, static_argnums=(0, 1))
def rw_metropolis_kernel(rng_key, logpdf, position, log_prob):
move_proposals = jax.random.normal(rng_key, shape=position.shape) * 0.1
proposal = position + move_proposals
proposal_log_prob = logpdf(proposal)
log_uniform = np.log(jax.random.uniform(rng_key, shape=position.shape))
do_accept = log_uniform < proposal_log_prob - log_prob
position = np.where(do_accept, proposal, position)
log_prob = np.where(do_accept, proposal_log_prob, log_prob)
return position, log_prob
def rw_metropolis_sampler(rng_key, logpdf, initial_position):
position = initial_position
log_prob = logpdf(initial_position)
yield position
while True:
position, log_prob = rw_metropolis_kernel(rng_key, logpdf, position, log_prob)
yield position
如果你熟悉 Numpy,那么你应该非常熟悉它的语法。JAX 和它有一些不同之处:
jax.numpy 充当 numpy 的替代。对于只涉及数组操作的函数,用 import jax.numpy as np 替换 import numpy as np,这会给你带来性能上的提升。
JAX 处理随机数生成的方式与其他 Python 包不同,这是有原因的 (请阅读这篇文章:https://github.com/google/jax/blob/master/design_notes/prng.md ) 。每个发行版都以一个 PRNG 键作为输入。
因为 JAX 不能编译生成器,我从采样器中提取内核。因此,我们提取并 JIT 完成所有繁重工作的函数:rw_metropolis_kernel。
我们需要对 JAX 的编译器提供一点帮助,即指出当函数多次运行时哪些参数不会改变:@partial(jax.jit, argnums=(0, 1))。如果将函数作为参数传递,这是必需的,并且可以启用进一步的编译时优化。
Tensorflow Probability
对于 TFP,我们使用库中实现的随机游走 Metropolis 算法:
from functools import partial
import numpy as np
import tensorflow as tf
import tensorflow_probability as tfp
tfd = tfp.distributions
def run_raw_metropolis(n_dims, n_samples, n_chains, target):
samples, _ = tfp.mcmc.sample_chain(
num_results=n_samples,
current_state=np.zeros((n_dims, n_chains), dtype=np.float32),
kernel=tfp.mcmc.RandomWalkMetropolis(target.log_prob, seed=42),
num_burnin_steps=0,
parallel_iterations=8,
)
return samples
run_mcm = partial(run_tfp_mcmc, n_dims, n_samples, n_chains, target)
## Without XLA
run_mcm()
## With XLA compilation
tf.xla.experimental.compile(run_mcm)
结果
我们有两个自由维度:样本的数量和链的数量,第一个依赖于原始的数字处理能力,第二个也依赖于向量化的实现方式。因此,我决定在两个维度上对算法进行基准测试。
我考虑以下情况:
Numpy 实现;
JAX 实现;
减去编译时间的 JAX 实现。这只是一个假设的情况,目的是显示编译带来的改进。
Tensorflow Probability;
实验 XLA 编译的 Tensorflow Probability。
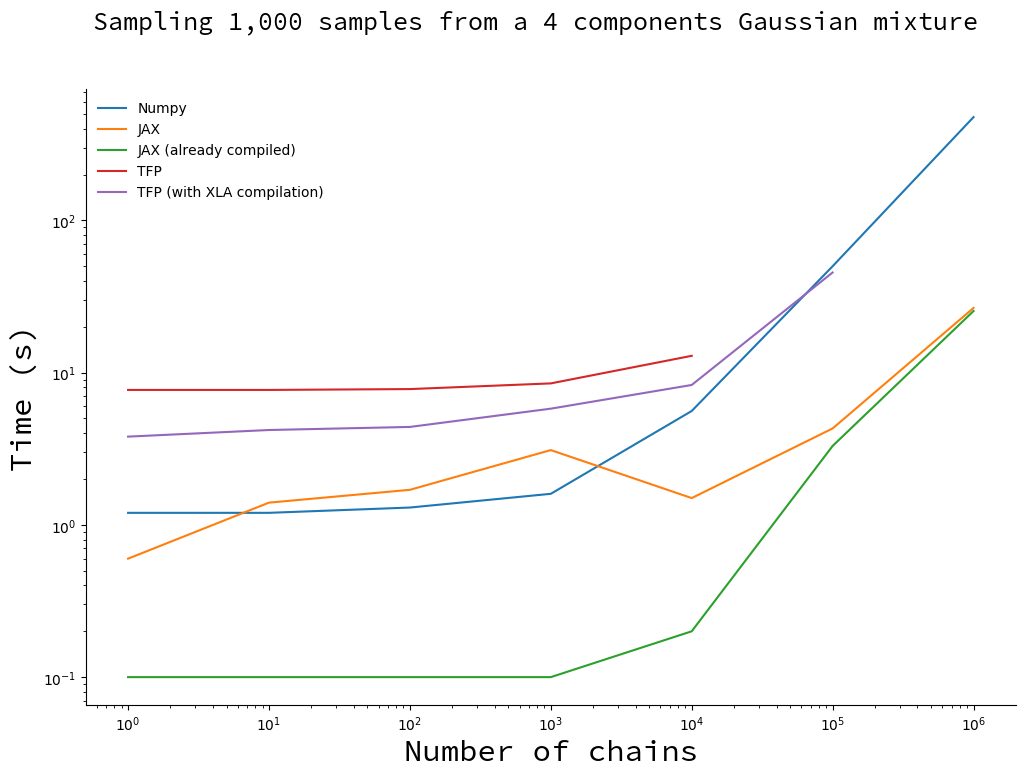
用 1000 条链绘制越来越多的样本
我们固定链的数量,并改变样本的数量。

你将注意到 TFP 实现的缺失点。由于 TFP 算法存储所有的样本,所以它会耗尽内存。这在 XLA 编译的版本中没有发生,可能是因为它使用了内存效率更高的数据结构。
对于少于 1000 个样本,普通的 TFP 和 Numpy 实现比它们的编译副本要快。这是由于编译开销造成的:当你减去 JAX 的编译时间 (从而获得绿色曲线) 时,它会大大加快速度。只有当样本的数量变得很大,并且总抽样时间取决于抽取样本的时间时,你才开始从编译中获益。
没有什么神奇的:JIT 编译意味着一个明显的、但不变的计算开销。
我建议在大多数情况下使用 JAX。只有当相同的代码执行超过 10 次时,在 0.3 秒而不是 3 秒内进行采样的差异才会产生影响。然而,编译是只会发生一次。在这种情况下,计算开销将在你达到 10 次迭代之前得到回报。实际上,JAX 赢了。
用越来越多的链绘制 1000 个样本
在这里,我们固定样本的数量,改变链的数量。

JAX 仍然明显地赢了:只要链的数量达到 10,000,它就比 Numpy 更快。你将注意到 JAX 曲线上有一个凸起,这完全是由于编译造成的 (绿色曲线没有这个凸起)。我不知道为什么,如果有答案请告诉我!
这就是令人兴奋的亮点:
JAX 可以在 25 秒内在 CPU 上生成 10 亿个样本,比 Numpy 快 20 倍!
结论
对于允许我们用纯 python 编写代码的项目,JAX 的性能是令人难以置信的。Numpy 仍然是一个不错的选择,特别是对于那些 JAX 的大部分执行时间都花在编译上的项目来说尤其如此。
但是,Numpy 不适合概率编程语言。如 Hamiltonian Monte Carlo 这样的高效抽样算 Uber 优步的团队开始和 JAX 在 Numpyro 上合作。
不要过多地解读 Tensorflow Probability 的拙劣表现。当从分布中采样时,重要的不是原始速度,而是每秒有效采样的数量。TFP 的实现包括更多的附加功能,我希望它在每秒有效采样样本数方面更具竞争力。
最后,请注意,用链的数量乘以样本的数量要比用样本的数量乘以样本的数量容易得多。我们还不知道如何处理这些链,但我有一种直觉,一旦我们这样做了,概率编程将会有另一个突破。
via:https://rlouf.github.io/post/jax-random-walk-metropolis/
雷锋网雷锋网雷锋网

正在生成分享图...
 吴彤
吴彤