本文为 AI 研习社编译的技术博客,原标题 :
Introducing Google Research Football: A Novel Reinforcement Learning Environment
作者 | Karol Kurach、Olivier Bachem
翻译 | 汪鹏 编辑 | 王立鱼
原文链接:
https://ai.googleblog.com/2019/06/introducing-google-research-football.html
强化学习(RL)的目标是培养能够与环境互动并解决复杂任务的智能体,实现在机器人,自动驾驶汽车等领域中的实际应用。通过让智能体玩游戏,如标志性的 Atari console games , Alphago ,或大型游戏,如Dota 2或魔兽世界 2 ,所有这些都提供了新算法和新算法的挑战性环境,推动了这一领域的快速发展。可以以安全,可重复的方式快速测试想法。对于RL来说,足球比赛尤其具有挑战性,因为它需要在短期控制,学习概念(如传球)和高水平战略之间实现自然平衡。
今天我们很高兴地宣布推出 Google Research Football Environment,这是一个全新的RL环境,智能体的目标是掌握世界上最受欢迎的体育足球。以流行的足球游戏为模型,足球环境提供基于物理的3D足球模拟,其中智能体控制他们团队中的一个或所有足球运动员,学习如何在他们之间传球,并设法克服对手的防守以进球。足球环境提供了几个关键组件:高度优化的游戏引擎,一系列严格的研究问题,称为足球基准,以及足球学院,一组逐步变硬的RL场景。为了便于研究,我们在Github上发布了基础开源代码的测试版。
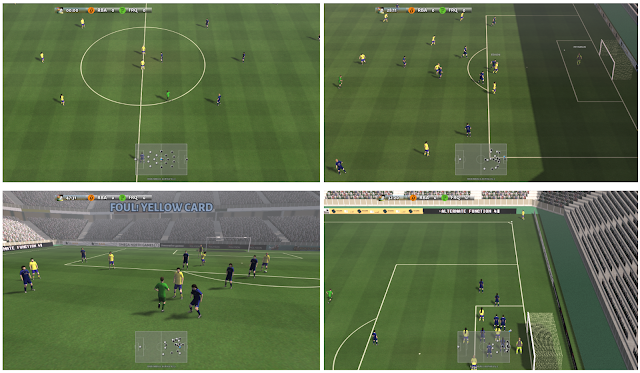
足球环境的核心是一个高级的足球模拟,称为足球引擎,它基于大量修改版本的游戏足球。根据两支对方球队的输入动作,它模拟了足球的比赛,包括进球,犯规,角球和点球,以及越位。 足球引擎采用高度优化的C ++代码编写,允许它在现成的机器上运行,无论是GPU还是没有基于GPU的渲染。这使其在单个六核机器上达到每天大约2500万步的性能。
足球引擎是一种先进的足球模拟,支持所有主要的足球规则,如开球(左上),进球(右上),犯规,牌(左下),角球和点球(右下)和越位。
足球引擎还具有针对RL的额外功能。首先,它允许从不同的状态表示中学习,这些状态表示包含诸如玩家位置之类的语义信息,以及从原始像素学习。其次,为了研究随机性的影响,它可以在随机模式(默认启用)中运行,其中在环境和对手AI动作中都存在随机性,并且在确定性模式中,其中没有随机性。第三,足球引擎开箱即用,与广泛使用的OpenAI Gym API兼容。最后,研究人员可以通过使用键盘或游戏手柄与对方或其代理人对战来获得对游戏的感觉。
通过足球基准测试,我们为基于足球引擎的RL研究提出了一系列基准问题。这些基准的目标是针对固定的基于规则的对手进行足球的“标准”游戏,该对手是为此目的而手工设计的。我们提供三个版本:简单足球难度,中等难度和困难难度,对手的实力不同。
作为参考,我们提供两种最先进的强化学习算法的基准测试结果:DQN和IMPALA,它们既可以在一台机器上的多个过程中运行,也可以在多台机器上同时运行。我们研究了为算法提供的唯一奖励是获得的目标以及我们为将球移近目标而提供额外奖励的设置。
我们的研究结果表明,足球基准是各种困难的有趣研究问题。特别是,简单足球难度似乎适用于单机算法的研究,而足球困难基准则证明即使对于大规模分布式RL算法也具有挑战性。基于环境的性质和基准的难度,我们期望它们可用于研究当前的科学挑战,例如样本有效RL,稀疏奖励或基于模型的RL。
不同基线的不同难度级别的代理与对手的平均目标差异。 简单的对手可以被训练为2000万步的DQN代理打败,而中等和困难的对手需要分布式算法,例如训练2亿步的IMPALA
完整足球基准下,训练智能体可能具有挑战性,我们还提供足球学院,各种难度的各种场景。这使研究人员能够开始研究新的研究思路,允许测试高级概念(例如传递),并为研究课程学习研究思路提供基础,智能体可以从逐渐困难的情景中学习。足球学院场景的示例包括智能体必须学习如何针对空目标进行评分的设置,他们必须学习如何在玩家之间快速传递,以及他们必须学习如何执行反击。使用简单的API,研究人员可以进一步定义自己的场景并训练代理来解决它们。
热门:一个成功的策略,朝着目标(根据需要,因为一些对手追逐我们的球员)和对阵守门员的比分。第二:驾驶和完成反击的美妙方式。第三:解决2对1比赛的简单方法。底部:角球后角球得分。
足球基准和足球学院考虑标准的RL设置,其中智能体与固定的对手竞争,即,对手可以被认为是环境的一部分。然而,实际上,足球是一个双人游戏,两个不同的团队竞争,而一个人必须适应对方团队的行动和战略。足球引擎为研究这种环境提供了独特的机会,一旦我们完成了实现自我发挥的持续努力,就可以研究更有趣的研究设置。雷锋网雷锋网雷锋网
想要继续查看该篇文章相关链接和参考文献?
点击【谷歌发布一个新的强化学习环境:Google Research Football】即可访问!
今日资源推荐:
一份可以作为Python编程语言的指南或者教程。它主要是为新手而设计,不过对于有经验的程序员来说,它同样有用。即便你对计算机的了解只是如何在计算机上保存文本文件,你都可以通过本书学习Python。如果你有编程经验,你也可以使用本书学习Python。

正在生成分享图...
 高秀松
高秀松