雷锋网 AI 科技评论按:CMU 博士、UC Santa Barbara 计算机科学系助理教授王威廉(William Wang)是学术圈内的积极分子,研究领域涵盖信息提取、社交媒体、语言和视觉、口语处理、机器学习理论和知识图谱等。王威廉也是社交媒体红人。
王威廉组的学术研究非常活跃,小组内常有顶会论文出现。根据王威廉微博介绍,他们组有 6 篇论文被自然语言处理顶级会议 NAACL 2019 接收,其中甚至包括来自二年级本科生同学的论文。近日随着 CVPR 2019 发榜,王威廉组王鑫同学与微软研究院的合作文章《Reinforced Cross-Modal Matching & Self-Supervised Imitation Learning for Vision-Language Navigation》也被 CVPR 接收。王威廉表示,“本文是CVPR满分文章(3个Strong Accept),在5165篇投稿文章中审稿得分排名第一。今天被程序委员会和领域主席评审团确定为CVPR口头报告论文,我们将在夏天在洛杉矶长滩市进行报告。”
雷锋网 AI 科技评论把论文内容简单介绍如下。
Reinforced Cross-Modal Matching & Self-Supervised Imitation Learning for Vision-Language Navigation
用于视觉-语言导航的强化跨模态匹配及自我监督模仿学习
论文地址:http://arxiv.org/abs/1811.10092
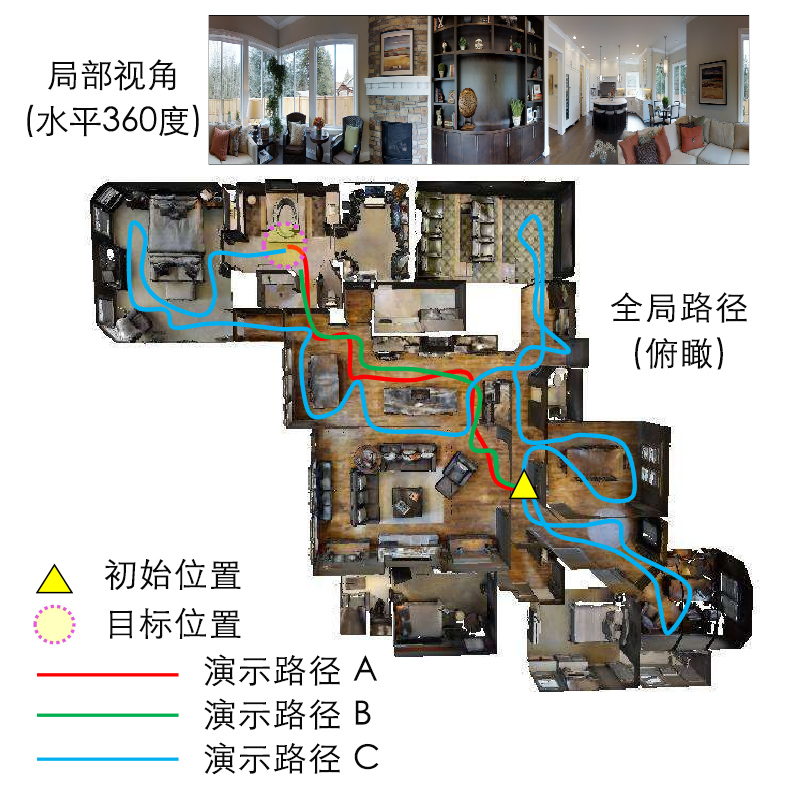
论文简介:视觉-语言导航(Vision-language navigation,VLN)任务是指在真实的三维环境中让具有实体的智能体进行导航并完成自然语言指令。在这篇论文中,作者们研究了如何解决这个任务中的三个重点挑战:跨模态参照,糟糕的反馈,以及泛化问题。作者们首先提出了一种新的强化跨模态匹配(RCM)方法,它可以通过强化学习的方式同时促进局部和全局的跨模态参照。具体来说,他们使用了一个匹配指标,它成为了鼓励模型增强外部指令和运动轨迹之间匹配的固有反馈;模型也使用了一个推理导航器,它用来在局部视觉场景中执行跨模态参照。在一个 VLN benchmark 数据集上进行的评估结果表明,作者们提出的 RCM 模型大幅超越已有模型,SPL 分数提高了 10%,成为了新的 SOTA。为了提高学习到的策略的泛化性,作者们还进一步提出了一个自监督模仿学习(SIL)方法,通过模仿自己以往的良好决策的方式探索未曾见过的环境。作者们表明了 SIL 可以逼近出更好、更高效的策略,这极大程度减小了智能体在见过和未见过的环境中的成功率表现的差别(从 30.7% 降低到 11.7%)。

由于他们提出的学习框架是模块化的、不依赖模型的,其中的组件未来都可以继续分别作出改进。论文中的 ablation study 也表明了每个组件各自的效果。
论文原文见 http://arxiv.org/abs/1811.10092
雷锋网 AI 科技评论报道

正在生成分享图...
 AI科技评论
AI科技评论