雷锋网 AI 科技评论按:本文作者石塔西,原载于知乎,雷锋网已获授权。
本文是对阿里的论文《Image Matters: Visually modeling user behaviors using Advanced Model Server》的解读。
初读此文的标题和摘要,又有 image,又有 CTR,我以为是一种新型的 CNN+MLP 的联合建模方法。读下来才知道,本文的重点绝不在什么图像建模上,压根就没 CNN 什么事。想像中的像素级别的建模根本没有出现,商品的图片利用网上可下载的预训练好的 VGG16 模型的某个中间层压缩成 4096 维向量,作为 CTR 模型的原始输入。
而将图片引入到推荐/搜索领域,也不是什么新鲜事。不说论文 Related Works 中提到的工作,我自己就做过基于图片的向量化召回,结构与论文图 4 中的 Pre-Rank DICM 结构很相似,只不过用户侧不包含他之前点击过的商品图片罢了,在此略下不表。
没有提出新的图像建模方法,也并非第一次在推荐算法中使用图片信息,那么此文的创新点到底在哪里?我觉得,本文的创新点有两个创新点:
之前的工作尽管也在推荐/搜索算法中引入了图片信息,可是那些图片只用于物料侧,用于丰富商品、文章的特征表示。而阿里的这篇论文,是第一次将图片用于用户侧建模,基于用户历史点击过的图片(user behavior images)来建模用户的视觉偏好。
接下来会看到,将图片加入到用户侧建模,理论上并不复杂,理论上用传统 PS 也可以实现,起码跑个实验,发篇论文应该不成问题。但是,如果应用到实际系统,图片特征引入的大数据量成为技术瓶颈。为此,阿里团队为传统 PS 的 server 也增加了「模型训练」功能,并称新结构为 Advanced Model Server(AMS)。
基于历史点击图片建模用户视觉偏好
先谈一下第一个「小创新」。之所以说其「小」,是因为通过预训练的 CNN 模型提取特征后,每张图片用一个高维(比如 4096)稠密向量来表示。这些图片向量,与常见的稀疏 ID 类特征经过 embedding 得到的稠密向量,没有质的区别(量的区别,下文会提到),完全可以复用以前处理 ID embedding 的方法(如 pooling, attention)来处理。
Deep Image CTR Model(DICM)的具体结构如下所示:

DICM 架构图
如果只看左边,就是推荐/搜索中常见的 Embedding+MLP 结构。注意上图中的 Embedding+MLP 结构只是实际系统的简化版本,实际系统中可以替换成 Wide&Deep, DIN, DIEN 等这些「高大上」的东西。
假设一个满足要求的图片 embedding model 已经 ready,即图中的 embmodel。商品的缩略图,经过 embmodel 压缩,得到商品的图片信息(图中的粉红色块)
右边部分,负责利用图片建模用户。将每个用户点击过的图片(user behavior image),经过 embmodel 进行压缩(图中的蓝色块)。它们与商品图片(ad image)的 embedding 结果(粉红色块)经过 attentive pooling 合并成一个向量(桔色块)表示用户的视觉偏好
将用户点击过的多张图片的向量(蓝色)合并成一个向量(桔色),其思路与 Deep Interest Network 基于 attention 的 pooling 机制大同小异,只不过要同时考虑「id 类特征」与「商品图片」对用户历史点击图片的 attention,称为 MultiQueryAttentivePooling。
第 1 步得到基于 id 特征的 embedding 结果,与第 2 步得到的商品图片 (ad image) 的 embedding 结果(粉红色),与第 3 步得到的表示用户兴趣偏好的向量(桔红色),拼接起来,传入 MLP,进行充分的交互
这个模型的优势在于:
之前的模型只考虑了传统的 ID 类特征和物料的图像信息,这次加入了用户的视觉偏好,补齐了一块信息短板
不仅如此,通过 MLP,将传统的 ID 类特征、物料的图像信息、用户的视觉偏好进行充分交互,能够发现更多的 pattern。
基于用户历史访问的 item id 来建模用户的兴趣,始终有「冷启动」问题。如果用户访问过一个 embedding matrix 中不存在的 item,这部分信息只能损失掉。而基于用户历史访问的图片来建模,类似于 content-based modeling,商品虽然是新的,但是其使用的图片与模型之前见过的图片却很相似,从而减轻了「冷启动」问题。
综上可见,DICM 的思路、结构都很简单。但是,上面的描述埋了个大伏笔:那个图片嵌入模型 embmodel 如何设计?没有加入图片、只有稀疏的 ID 类特征时,Embedding+MLP 可以通过 Parameter Server 来分布式训练。现在这个 embmodel,是否还可以在 PS 上训练?在回答这个问题之前,让我们先看看稀疏 ID 特征 Embedding+MLP 在传统的 PS 上是如何训练的?
稀疏 ID 特征 Embedding+MLP 在传统的 PS 上是如何训练的?
介绍 PS 的论文、博客汗牛充栋,实在论不上我在这里炒冷饭,但是,我还是要将我实践过的「基于 PS 训练的 DNN 推荐算法」,在这里简单介绍一下,因为我觉得它与《Scaling Distributed Machine Learning with the Parameter Server》所介绍的「经典」PS 还是稍稍有所不同,与同行们探讨。
基于 PS 的分布式训练的思想还是很简单的:
1.一开始是 data parallelism。每台 worker 只利用本地的训练数据前代、回代,计算 gradient,并发往 server。Server 汇总(平均)各 worker 发来的 gradient,更新模型,并把更新过的模型同步给各 worker。这里有一个前提,就是数据量超大,但是模型足够小,单台 server 的内存足以容纳。
2.但是,推荐/搜索系统使用超大规模的 LR 模型,模型参数之多,已经是单台 server 无法容纳的了。这时 Parameter Server 才应运而生,它同时结合了 data parallelism 与 model parallelism
Data parallelism:训练数据依然分布地存储在各台 worker node 上,各 worker node 也只用本地数据进行计算。
Model parallelism:一来模型之大,单台 server 已经无法容纳,所以多台 server 组成一个分布式的 key-value 数据库,共同容纳、更新模型参数;二来,由于推荐/搜索的特征超级稀疏,各 worker 上的训练数据只涵盖了一部分特征,因此每个 worker 与 server 之间也没有必要同步完整模型,而只需要同步该 worker 的本地训练数据所能够涵盖的那一部分模型。
所以按照我的理解,PS 最擅长的是训练稀疏数据集上的算法,比如超大规模 LR 的 CTR 预估。但是,基于 DNN 的推荐/搜索算法,常见模式是稀疏 ID 特征 Embedding+MLP,稍稍有所不同
1.稀疏 ID 特征 Embedding,是使用 PS 的理想对象:超大的 embedding 矩阵已经无法容纳于单台机器中,需要分布式的 key-value 数据库共同存储;数据稀疏,各 worker 上的训练数据只涵盖一部分 ID 特征,自然也只需要和 server 同步这一部分 ID 的 embedding 向量。
2.MLP 部分,稍稍不同
和计算机视觉中动辄几百层的深网络相比,根据我的经验,纵使工业级别的推荐/搜索算法,MLP 也就是 3~4 层而已,否则就有过拟合的风险。这等「小浅网络」可以容纳于单台机器的内存中,不需要分布式存储。
与每台 worker 只需要与 server 同步本地所需要的部分 embedding 不同,MLP 是一个整体,每台 worker 都需要与 server 同步完整 MLP 的全部参数,不会只同步局部模型。
所以,在我的实践中
稀疏 ID 特征 Embedding,就是标准的 PS 做法,用 key-value 来存储。Key 就是 id feature,value 就是其对应的 embedding 向量;
MLP 部分,我用一个 KEY_FOR_ALL_MLP 在 server 中存储 MLP 的所有参数(一个很大,但单机足以容纳的向量),以完成 worker 之间对 MLP 参数的同步。
实际上,对 Embedding 和 MLP 不同特性的论述,在《Deep Interest Network for Click-Through Rate Prediction》中也有所论述。阿里的 X-DeepLearning 平台
用 Distributed Embedding Layer 实现了分布式的 key-value 数据库来存储 embedding。应该是标准的 PS 做法。
用 Local Backend 在单机上训练 MLP。如何实现各 worker(i.e., local backend)的 MLP 的同步?是否和我的做法类似,用一个 key 在 server 上存储 MLP 的所有参数?目前尚不得而知,还需要继续研究。
加入图片特征后,能否继续在 PS 上训练?
按原论文的说法,自然是不能,所以才提出了 AMS。一开始,我以为」PS 不支持图片」是「质」的不同,即 PS 主要针对稀疏特征,而图片是稠密数据。但是,读完文章之后,发现之前的想法是错误的,稀疏 ID 特征与图片特征在稀疏性是统一的。
某个 worker node 上训练样本集,所涵盖的 item id 与 item image,只是所有 item ids/images 的一部分,从这个角度来说,item id/image 都是稀疏的,为使用 PS 架构提供了可能性
item image 经过 pre-trained CNN model 预处理,参与 DICM 训练时,已经是固定长度的稠密向量。Item id 也需要 embedding 成稠密向量。从这个角度来说,item id/image 又都是稠密的。
正因为稀疏 ID 特征与图片特征,本质上没有什么不同,因此 PS 无须修改,就可以用于训练包含图片特征的 CTR 模型(起码理论上行得通),就是文中所谓的 store-in-server 模式。
图片特征存入 PS 中的 server,key 是 image index,value 是经过 VGG16 提取出来的稠密向量
训练数据存放在各 worker 上,其中图片部分只存储 image index
训练中,每个 worker 根据各自本地的训练集所包含的 image index,向 server 请求各自所需的 image 的 embedding,训练自己的 MLP
一切看上去很美好,直到我们审视 VGG16 提取出来的 image embedding 到底有多长?
原论文中提到,经过试验,阿里团队最终选择了 FC6 的输出,是一个 4096 长的浮点数向量。而这仅仅是一张图片,每次迭代中,worker/server 需要通信的数据量是 mini-batch size * 单用户历史点击图片数 (i.e., 通常是几十到上百) * 4096 个浮点数。按照原论文中 table 2 的统计,那是 5G 的通讯量。
而一个 ID 特征的 embedding 才用 12 维的向量来表示。也就是说,引入 image 后,通讯量增长了 4096/12=341 倍。
(或许有心的读者问,既然 4096 的 image embedding 会造成如此大的通讯压力,那为什么不选择 vgg16 中小一些层的输出呢?因为 vgg16 是针对 ImageNet 训练好的,而 ImageNet 中的图片与淘宝的商品图片还是有不小的差距(淘宝的商品图片应该很少会出现海象与鸭嘴兽吧),因此需要提取出来的 image embedding 足够长,以更好地保留一些原始信息。原论文中也尝试过提取 1000 维的向量,性能上有较大损失。)
正是因为原始图片 embedding 太大了,给通信造成巨大压力,才促使阿里团队在 server 上也增加了一个「压缩」模型,从而将 PS 升级为 AMS。
AMS 的技术细节,将在下一节详细说明。这里,我觉得需要强调一下,由于加入图片而需要在 AMS,而不是 PS 上训练,这个变化是「量」变引起的,而不是因为原来的 ID 特征与图片这样的多媒体特征在「质」上有什么不同。比如,在这个例子中,
使用 AMS 是因为 image 的原始 embedding 由 4096 个浮点数组成,太大了
之所以需要 4096 个浮点数,是因为 vgg16 是针对 ImageNet 训练的,与淘宝图片相差较大,所以需要保留较多的原始信息
如果淘宝专门训练一个针对商品图片的分类模型,那么就有可能拿某个更接近 loss 层、更小的中间层的输出作为 image embedding
这样一来,也就没有通信压力了,也就无需 server 上的「压缩」模型了,传统的 PS 也就完全可以胜任了。
所以,AMS 并不应该是接入多媒体特征后的唯一选择,而 AMS 也不仅仅是针对多媒体特征才有用。应该说,AMS 应该是针对「embedding 过大、占有过多带宽」的解决方案之一。
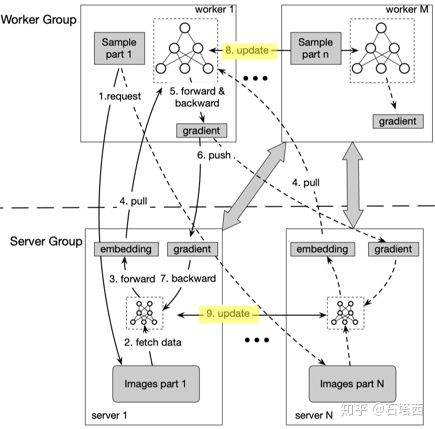
Advanced Model Server(AMS)架构
上一节讲清楚了,AMS 是为了解决「image 的原始 embedding 过大,造成太大通信压力」的问题而提出的。在这一节里,我们来看看 AMS 是如何解决这一问题的。
AMS 的解决方案也很简单:
为每个 server 增加一个可学习的「压缩」模型(论文中的 sub-model,其实就是一个 4096-256-64-12 的金字塔型的 MLP)
当 worker 向 server 请求 image embedding 时,server 上的「压缩」模型先将原始的 4096 维的 image embedding 压缩成 12 维,再传递给 worker,从而将通讯量减少到原来的 1/340
该「压缩」模型的参数,由每个 server 根据存在本地的图片数据学习得到,并且在一轮迭代结束时,各 server 上的「压缩」模型需要同步。
每个 server 上都有这样一个这个可学习的「压缩」模型,要能够利用存放在本地的数据(这里就是 4096 长的 image 原始 embedding)前代、回代、更新权重,并且各 server 的模型还需要同步,简直就是 worker 上模型的翻版。将 worker 的「训练模型」的功能复制到 server,这也就是 Advanced Model Server 相比于传统 Parameter Server 的改进之处。
AMS 是本文最大的创新点。本来还想再费些笔墨详细描述,最后发现不过是对原论文 4.2 节的翻译,白白浪费篇幅罢了,请读者移步原论文。其实,当你明白了 AMS 要解决什么样的问题,那么原论文中的解决方案,也就是一层窗户纸罢了,简单来说,就是将 worker 上的模型前代、回代、更新、同步代码移植到 server 端罢了。最后加上原论文中的图 2,以做备忘。

AMS 交互流程
总结
以上就是我对 Deep Image CTR Model(DICM)两个创新点的理解。根据原论文,无论是离线实验还是线上 AB 测试,DICM 的表现都比不考虑用户视觉偏好的老模型要更加优异。DICM 开启了在推荐系统中引入多媒体特征的新篇章。
小结一下 DICM 的成就与思路:
DICM,第一次将图片信息引入到用户侧建模,通过用户历史上点击过的图片(user behavior images)建模用户的视觉偏好,而且将传统的 ID 类特征、物料的图像信息、用户的视觉偏好进行充分交互,能够发现更多的 pattern,也解决了只使用 ID 特征而带来的冷启动问题。
但是,引入 user behavior images 后,由于 image 原始 embedding 太大,给分布式训练时的通信造成了巨大压力。为此,阿里团队通过给每个 server 增加一个可学习的「压缩」模型,先压缩 image embedding 再传递给 worker,大大降低了 worker/server 之间的通信量,使 DICM 的效率能够满足线上系统的要求。这种为 server 增加「模型训练」功能的 PS,被称为 AMS。
最后,还应该强调,引发 PS 升级到 AMS 的驱动力,是「量变」而不是「质变」。图片之类的多媒体特征,既不是 AMS 的唯一用武之地,也不应是 AMS 垄断的专利。选择哪种训练架构,需要我们根据业务、数据的特点做出判断,切忌迷信「银弹」。

正在生成分享图...
 nebula
nebula