本文为 AI 研习社编译的技术博客,原标题 :
Deep Dive into Math Behind Deep Networks
作者 | Piotr Skalski
翻译 | 灰灰在学习、Disillusion
校对 | 酱番梨 整理 | 菠萝妹
原文链接:l
https://towardsdatascience.com/https-medium-com-piotr-skalski92-deep-dive-into-deep-networks-math-17660bc376ba
如今,我们拥有许多高级的,特殊的库与框架,比如 Keras,TensorFlow或者PyTorch,也不再总需要担心权重矩阵的大小,更不需要记住我们决定使用的激活函数导数的公式。通常我们只需要尽力一个神经网络,即使是一个结构非常复杂的神经网络,也只需要导入和几行代码就可以完成了。这节省了我们搜索漏洞的时间并简化了我们的工作。但是,对于神经网络的深入了解对我们完成在构架选择,或者超参数的调整或优化的任务上有着很大的帮助。
注意:感谢Jung Yi Lin 的帮助,你也可以阅读中文版的这篇文章。我在GitHub上提供了用于创建本文中使用的可视化的源代码。
了解更多的神经网络的工作原理。我决定在今年夏天抽出点时间深入的学习一下数学。我也打算写一篇关于最新的学习咨询的文章,以便帮助别人理解一些生涩难懂的概念。我编写的这篇文章会对那些不太擅长线性代数和微积分的人十分友好,但就像标题所暗示的,这将是一篇与数学密切相关的文章。
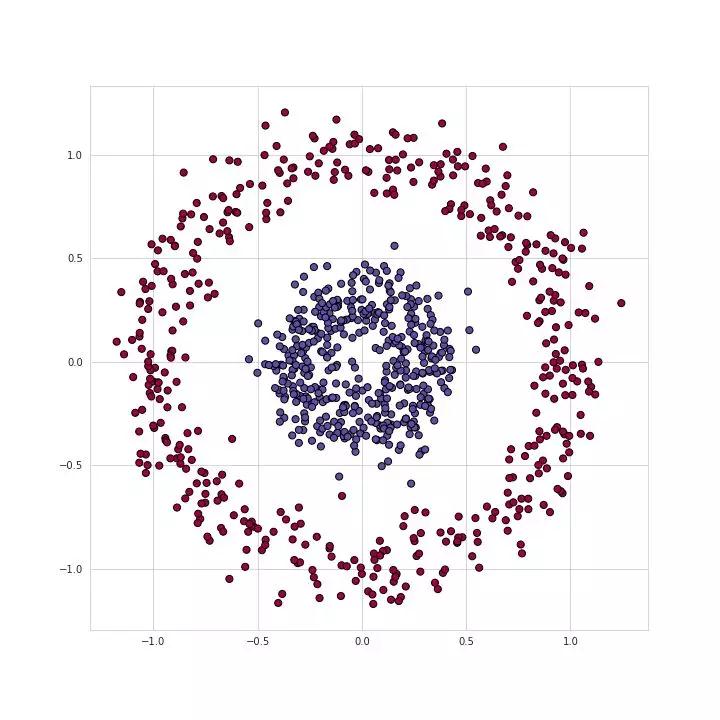
图1.训练集的可视化
举一个例子:我们将解决确定二进制分类数据集问题,如下面图一所示。如果两个类不同那就会形成两个圆圈——这种设置非常不方便在许多传统的ML算法中,但是再一些小型神经网络中却可以有很好的效果。为了解决这个问题,我们将使用具有图二结构的神经网络——5个具有不同数量单位的全连接层。对于隐藏层,我们将使用relu作为其激活函数,而将Sigmod作为输出层。这是相当简单的一种构造,而不是复杂到足以成为一个需要我们深思熟虑的一个例子。
图2.神经网络架构
首先,我们用最流行的机器学习库之一——KERAS提出了第一种解决方法。
from keras.models import Sequential
from keras.layers import Dense
model = Sequential()
model.add(Dense(4, input_dim=2,activation='relu'))
model.add(Dense(6, activation='relu'))
model.add(Dense(6, activation='relu'))
model.add(Dense(4, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(X_train, y_train, epochs=50, verbose=0)就像这样。正如我在介绍中提到的,一些导入加几行代码就足以创建并且训练一个能够对我们的测试集中的样本进行几乎100%分类的模型了。我们的任务归根结底就是根据设定超参数(层数,层中神经元数,激活函数或时期数)选择神经网络的结构。现在让我们看一看训练背后的过程。哦......我在学习过程中创建了一个很酷的可视化界面。希望你看了以后不会难以入睡。
图3.对训练合适的类进行可视化展示
让我们先回答一个问题:什么是神经网络?它是一种生物学启发的构建计算机程序的方法,能够学习和独立地找到数据中的连接。正如图二所展示的。网络是层叠排列的软件“神经元”的集合,他们以允许通信的方式连在一起。
单个神经元
每个神经元接收一组x值(编号从1到n)作为输入并计算预测的y^值。向量X是训练集中m个样本之一的特征值的量化。更重要的是每个单元都有自己的一组参数,通常要用到在学习过程中不断变化的w(权重列向量)和b(偏差值),在每次迭代中神经元计算向量x的值的加权平均值,基于其当前的权重向量w并加上偏差,最后,该计算的结果通过非线性激活函数g()。我将在以后的部分中提及一些关于最流行的激活函数。
单个层
现在让我们往小的地方看,考虑如何对整个神经网络层进行计算。我们将运用我们所知的在单个神经元内部的原理,矢量化整个层,将这些计算结合到矩阵方程中。方程式将会被编写在选择层中,为了统一符号[l]。顺便说一下,下标i标记该层中神经元的索引。
图5,单个层
一个更重要的评价:当我们为一个单个单元编写方程时,我们使用x和y^,它们分别是特征值的列向量和预测值,当我们切换到图层的一般表示法时,我们使用向量a - 该向量可以激活相应的层。因此,x向量就可以激活层0——输入层,每个神经元都执行者如下所类似的计算:
为清楚起见,让我们写下如第二层的方程式:
正如你所看到的,对于每个层,我们必须执行许多非常类似的操作,因此其实for循环在此使用效率并不高,所以我们将其矢量化以加快运算,首先,我们将向量水平堆叠成一个N*1的向量。
我们将每个权重w进行转置以形成举证W,类似地,我们将层中的每个神经元的偏差堆叠在一起,从而创建垂直向量b,现在没有什么可以阻止我们构建一个矩阵方程,它可以使我们一次对层的所有神经元进行计算。让我们写下我们使用的矩阵和向量的维数。
多个矢量化例子
这个我们设置的方程式目前为止只包含一个例子。在神经网络的学习过程中,你通常使用大量数据,最多可达数百万条。因此,下一步将是矢量化多个例子。假设我们的数据集中有m个条目,每个条目都有nx个特征,首先,我们将每层的垂直向量x,a和z组合在一起,分别创建X,A和Z矩阵。然后我们重写先前布局的方程式,同时考虑新创建的矩阵。
激活函数是神经网络的关键元素之一,如果缺失了他们,那么我们的神经网络就只剩下线性函数的组成了。所以神经网络将直接成为一个线性函数。我们的模型也将缺失多样的扩展性,导致其甚至连逻辑回归都不如。
非线性的元素使得复杂的函数在学习过程中具有更好的灵活性和可塑性。我们选择激活函数的主要原因是,它能对学习速度有着重大影响,图6显示了一些常用的激活函数。目前,最受欢迎的隐藏层应该是ReLU函数,但是我们有时仍然会使用sigmoid,尤其是在输出层。当我们处理二进制分类时,我们希望模型返回的值在0到1的范围内。
图6.最流行的激活函数及其衍生物的图
促进深度学习的发展进程的基石可以说就是损失的值。一般来说,损失函数就是表示的我们理想值与现实值之间的差距。在我们的例子中,我们使用二进制交叉熵,但根据问题,我们还可以用不同的函数。我们使用的函数由以下公式表示,在图7中可以看到学习过程中其价值的变化。它显示了每次迭代时损失函数的值是如何减小同时使精确值增加。
图7.学习过程中精确值和损失值的变化
学习过程其实就是最小化损失值,通过改变W和参数的值。为了达到这个目标,我们从使用积分和梯度下降法去找到一个可以使loss值最小的函数。在每次迭代中我们将计算神经网络的每一部分的损失函数的偏导数的值。对于那些不太擅长这种计算的人,我就简单的说,导数具有很好的描述函数斜率的能力。由于我们知道如何改变变量使其在图表中向下移动。
为了形成关于梯度下降如何工作的直观理解(再次引起你的注意)我准备了一个小的可视化示意图。你可以看到我们从随机点走向最低点的每一步。在我们的神经网络中它以同样的方式工作——每次迭代的梯度都向我们展示了我们应该移动的方向。最主要的不同点是在我们的示范神经网络,我们有更多的参数需要考虑。但是...我们又如何计算这些全导数呢?
图8.实际中的梯度下降
正如我们所需要的,反向传播是一种可以让我们计算非常复杂的梯度的算法,我们可以根据以下公式调整神经网络的参数。
在上面的等式中,α表示学习率 —— 一个超参数,可以使你控制调整表现的参数。选择学习率至关重要 —— 如果我们通常将其设置得太低。我们的神经网络将非常缓慢地学习;如果我们设置得太高,我们无法达到最低限度。关于W和b的损失函数的偏导数dW和db,我们使用链式方法进行计算。dW和db矩阵的大小与W的大小相同。图9显示了神经网络中的操作顺序。我们清楚地看到前向和后向传播如何一起工作以优化损失函数。
图9.前向和后向传播
希望我已经解释了在神经网络中发生的数学。在使用神经网络时,至少基本了解这个过程是非常有用的。我认为我提到的这些事情是最重要的,但它们仅仅是冰山一角。我强烈建议你尝试自己编写这样一个小的神经网络,不使用高级框架,只使用Numpy。
如果你成功读到这里,恭喜你。这肯定不是一篇很简单的文章。如果你喜欢本文,请在Twitter和Medium上关注我,并查看我正在进行的其他项目,如GitHub和Kaggle。本文是“神经网络的奥秘”系列文章的第二篇,如果你还没有机会阅读其他文章。保持好奇!雷锋网
想要继续查看该篇文章相关链接和参考文献?雷锋网
长按链接点击打开或点击【深度网络揭秘之深度网络背后的数学】:
https://ai.yanxishe.com/page/TextTranslation/1161
AI研习社每日更新精彩内容,观看更多精彩内容:雷锋网
等你来译:

正在生成分享图...
 赖文昕
赖文昕