雷锋网 AI 科技评论按:随着互联网的飞速发展,图片成为信息传播的重要媒介,图片中的文本识别与检测技术也一度成为学界业界的研究热点,应用在诸如证件照识别、信息采集、书籍电子化等领域。
然而,一直以来存在的问题是,尚没有基于网络图片的、以中文为主的 OCR 数据集。基于这一痛点,阿里巴巴「图像和美」团队推出 MTWI 数据集,这是阿里首个公开的 OCR 数据集,也是现有难度最大、内容最丰富的网络图片 OCR 数据集。
基于该数据集,阿里巴巴「图像和美」团队联合华南理工大学共同举办 ICPR MTWI 2018 挑战赛,这场比赛共分为三个独立赛道,一是识别单文本行(列)图片中的文字,二是检测并定位图像中的文字行位置,三是识别整图中的文字内容。三场赛道各自独立,每场赛道都吸引了超过一千支队伍参赛。
来自 NELSLIP(National Engineering Laboratory for Speech and Language Information Processing,中科大语音及语言国家工程实验室)的杜俊教授、戴礼荣教授团队与科大讯飞合作,包揽全部三项任务的冠军。以下便是在这项比赛中分别负责识别和检测任务的中科大学生张建树和朱意星对比赛方案的描述,对于第三个赛道,他们则是结合了识别和检测的方案。
此次比赛中,主办方提供 20000 张图像作为数据集。其中 50% 作为训练集,50% 作为测试集。该数据集全部来源于网络图像,主要由合成图像、产品描述、网络广告构成,每一张图像或包含复杂排版,或包含密集的小文本或多语言文本,或包含水印,这对文本检测和识别均提出了挑战。以下是典型图片。

文本识别
这次比赛提交的方案大体上可以分为两种,一种是基于 CTC 的方案,另外一种是基于注意力的 Encoder-Decoder 方案。NELSLIP 团队根据复现结果,最终选定第二种方案。
比赛难点
首先是 OCR 长期面临的难题,比如连续文本,以及自然场景背景复杂,噪声干扰比较大。
其次,深度学习模型需要很大的数据量来进行训练。如果训练样本很少,很难将模型训练好。这次识别存在一些繁体字,而关于繁体字的训练样本比较少,会导致识别比较困难。
解决方案
Radical Analysis Network 网络
这次比赛 NELSLIP 团队用到 Radical Analysis Network,该网络主要用于解决少样本问题,这一网络基于张建树在 ICME2018 上的论文 Radical analysis network for zero-shot learning in printed Chinese character recognition,在比赛中做了一些优化,有如下明显优点:
这是一种基于注意力机制的编解码方法,而不是通过滑窗的形式来切分字符,不管输入是横排还是竖排,它只关注相应的像素点。
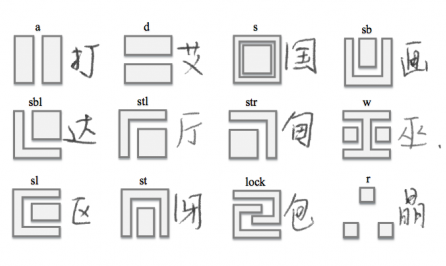
在这个方案之前,大家都是把汉字当成整个字符或一张图片来识别,所用到的方法跟图像识别,或者 ImageNet 图像分类的方案差不多,忽略了汉字本身的重要性质——汉字由偏旁部首构成。比赛中,他们以偏旁部首的形式将汉字拆解。拿「殿」字举例,这个字是左右结构,先是「共」字旁和「八」字旁行成上下结构,然后「尸」字旁左上包围这一上下结构。右边由「几」和「右」上下组成。

可以通过深度优先遍历的方式,将这种树形结构遍历成字符串的形式,然后再通过识别字符串来识别汉字。在这里有一个预先定义好的 IDS2char 字典。例如「聚」、「黔」、「坊」这三个字,将这些字的字符串识别出来之后,在字典里就能索引出结构类别,进而进行汉字识别。

这一方法可以带来两个好处:
汉字类别很多,通过拆解成偏旁部首,可以将数量大大压缩,去除掉冗余性。
虽然看起来把汉字拆解成了一个很长的序列,但实际上提高了运算速度。如果想将识别做得很好,肯定要涵括全部汉字,如果把一些古代用的字全部算上,字数达到 10 万。如果做一个十万种类别的分类器,效率将会很低。因此,虽说每个词的序列由原先的一被拆解成五、六或者更多,但序列中每个类别的类别数变少,搜索空间会相应变小,折中下来,解码效率相对得到提高。
能识别低频词,例如在训练集里没有出现过的词,这时候不需要额外收集数据,也不需要重新训练模型。
举个例子,之前很火爆的 duang 字,上成下龙。虽然这个字很简单,但是因为训练集中没有,普通的模型没办法识别,很有可能将其识别成「成」、「龙」或其他字。对 RAN 模型来说,可以在 OOV 场景下将其识别出来。例如把 duang 字作为输入,会解出成和龙,同时会出现一个表示成和龙上下结构的序列。

在识别繁体字时也是同理。
如下图所示,由于图像都是基于真实场景,所以出现了「薬」和「購」这样的繁体字。虽然一般的语言模型,能够将「代購」识别成「代购」,这在语义上是对的,但其实还是存在问题。通过 RAN 网络,就能很好地解决这里的 OOV 问题,正确识别出繁体字。

他们对 RAN 网络的改进还有一点,以前的网络是针对单字识别,模型的 encoder 只有一个 CNN,这一次的任务是文本行识别,为了建模文本的常识信息,他们在 encoder CNN 之后添加了一个双向 RNN 网络。另外,从单字识别到文本行识别,对于模型来说,这两者的隔阂不是特别大,在这里用来提取偏旁部首的注意力机制还可以区分字和字之间的间隔,实际上只需要在每个字的偏旁部首中间加上标志符。
针对注意力机制的改进
他们还对注意力机制进行了改进,以前是单 head 注意力机制,在此次比赛中,增加到 4-head 注意力机制,还额外在注意力上添加了一个 coverage actor,coverage actor 会把历史的注意力信息告诉当前时刻的注意力模型,这样能提高注意力的对齐能力。
另外,他们还使用了 attention guider 技术,除了把模型当成一个黑盒子让它自己学习,还会给注意力模型更强的指导。在这种真实场景的情况下,当噪声很大时,注意力模型很难学好,通过给予模型更好的指导,注意力会学得更快,模型也会收敛得更好。
RGB+HSV 主要用来解决通用 OCR 的一些问题,比如复杂的背景。一些通过人的眼睛看不清的图片可以通过 HSV 凸显出色调的差异性,从而就能正确识别。
此外,他们还做了一些数据增强工作,比如文本旋转,压缩等。
难以解决的案例:
第一种例子是背景噪声太大。如下图是人眼都看不清的比较复杂的例子。这个例子中背景是粉红色,前景是淡黄色,虽然可以通过 HSV 对图像进行色调增强,但可以看到,它的真实标注是漂亮宝贝 NO1,如果不用 HSV,结果错得很离谱。用了之后,漂亮两个字还是难以检测出来。

第二种例子是一些从真实场景中抠出来的图片,如果图片本身特别小,将其放大到一定程度,机器识别就会变得很模糊。
第三个比较难的例子就是前面提到的低频词问题,通过 RAN 网络可以正确识别。
检测
这次比赛中,检测存在四个方面的问题:
一是多角度问题。之前学术界的检测都是用矩形框标注的,比如检测沙发或人体,但如果做文本检测,比如一个 45 度角的倾斜文本,这时候如果用矩形框,就会多出来很多噪声。
二是文本之间的交叠问题。例如下面这幅图,两行字重叠在一起了。
三是文本模糊问题。如下图中框出来的部分,连人眼也看不清。
四是文本长度差距比较大。有的文本特别长,有的文本特别短。

针对这些问题的优化
这是此次比赛中使用的网络结构图,这是一个下采样过程,把不同尺寸下的特征进行了融合。

第二个要解决的是多角度问题。对于多角度问题,如果在第一步直接拟合四个顶点会产生歧义,为了避免这种情况,他们在第一步使用了 LocSLPR,会对输入图像构建空间金字塔,在各个尺度上描绘出文本的轮廓,从而完成文本行的准确定位。
这里使用了堆叠 R-CNN,第一次 proposal box 是水平矩形框,使用 LocSLPR 拟合轮廓,第二次的时候已经有了轮廓信息,所以第二步 proposal box 是旋转矩形框。

剩下的图片模糊问题靠神经网络的鲁棒性就可以解决,虽然说这一问题也比较难解决,但此次比赛中没有特意来设计网络。
比赛中碰到的实际问题
CVPR、ICCV 等计算机视觉会议上,每年都会有不少论文和方案,在这次比赛中,想拿第一名得参考各种不错的方案。
识别有一个比较大的难点,即有些图片过小,放大之后看不清楚,或者图片失真,图像分辨率不高,他们想做一些超分辨率的方法,提升放大后的图像质量,也筛选了 CVPR 上一些不错的超分辨率方案,但做完之后发现效果不是很理想,此外旋转上的一些问题也比较难解决。
另外,现在针对注意力的研究也非常多,包括 NLP,机器翻译等方向都有很多注意力机制的改进方案。但这些方案不是针对文本问题,所以在最开始尝试的时候并不能确定方案对任务的改进效果如何。在选择一些看起来比较合适的注意力机制方案进行改进和尝试的过程中,也遇到不少问题。
这一方案目前在手写字符识别上还需要改进。人在手写时,会非常随意,有时候会出现连笔,抹消掉了汉字本该有的偏旁部首和空间结构,这时候基于 RAN 的方法获得的性能提升就没有打印体的大。
未来,可能主要会针对注意力以及编码器进行改进。
雷锋网雷锋网

正在生成分享图...
 吴彤
吴彤