本文为雷锋网字幕组编译的技术博客 Happiness 2017,作者为 Javad Zabihi。
翻译 | Binpluto 整理 | 孔令双
雷锋网 AI 研习社:我们选择了 2017 幸福度数集,一个来自 Kaggle 平台的数集。这份数集给出了来自世界 155 个国家,关于包括家庭状况,平均寿命,经济水平,宽容度,对政府的信任感,自由度和反乌托邦残留在内的七方面因素的幸福等级和幸福值。这七项的分值之和就是幸福值,幸福值越高,幸福等级越低。因此,很显然七项中的每一项分值越高,意味着幸福水平越高 。我们将这七项因素定义为影响幸福的因素。反乌托邦是乌托邦的对立面,意味着最低的幸福水平。它将被视为其他国家判断他们离最不幸福国家有多远的参考对象。
我的报告包含了以下三部分:
净化
可视化
预测
选择这项任务的目的在于找出,哪些因素对人们过上幸福的生活更重要。根据结果,人们和国家可以专注于更关键的因素来实现更高的幸福水准。我们也将运用不同的机器学习算法来预测幸福值并比较预测结果,来判断哪一种算法更适用于这个数集。
现在我们可以导入数集并观察幸福变量的结构。我们的数集已经相当的整洁,不过,我们仍将会作出一点调整来使它看起来更好。
library(plyr)
library(dplyr)
library(tidyverse)
library(lubridate)
library(caTools)
library(ggplot2)
library(ggthemes)
library(reshape2)
library(data.table)
library(tidyr)
library(corrgram)
library(corrplot)
library(formattable)
library(cowplot)
library(ggpubr)
library(plot3D)
# World happiness report 2017
Happiness <- read.csv("../input/2017.csv")
str(Happiness)
## 'data.frame': 155 obs. of 12 variables:
## $ Country : Factor w/ 155 levels "Afghanistan",..: 105 38 58 133 45 99 26 100 132 7 ...
## $ Happiness.Rank : int 1 2 3 4 5 6 7 8 9 10 ...
## $ Happiness.Score : num 7.54 7.52 7.5 7.49 7.47 ...
## $ Whisker.high : num 7.59 7.58 7.62 7.56 7.53 ...
## $ Whisker.low : num 7.48 7.46 7.39 7.43 7.41 ...
## $ Economy..GDP.per.Capita. : num 1.62 1.48 1.48 1.56 1.44 ...
## $ Family : num 1.53 1.55 1.61 1.52 1.54 ...
## $ Health..Life.Expectancy. : num 0.797 0.793 0.834 0.858 0.809 ...
## $ Freedom : num 0.635 0.626 0.627 0.62 0.618 ...
## $ Generosity : num 0.362 0.355 0.476 0.291 0.245 ...
## $ Trust..Government.Corruption.: num 0.316 0.401 0.154 0.367 0.383 ...
## $ Dystopia.Residual : num 2.28 2.31 2.32 2.28 2.43 ...
我们已经观察了包含在数集内的变量,他们对应的类,以及每一个变量中的前几个观察项。事实上,这个数集含有 155 个观察项和 12 个变量。我认为一些变量名还不够明了,于是决定改掉其中一些变量名。同时,盒须低和盒须高的变量将从数据集中移除,因为这些变量只能使幸福值的可靠区间变得更低或更高而对于可视化和预测方面没有实际意义。
# Changing the name of columns
colnames (Happiness) <- c("Country", "Happiness.Rank", "Happiness.Score",
"Whisker.High", "Whisker.Low", "Economy", "Family",
"Life.Expectancy", "Freedom", "Generosity",
"Trust", "Dystopia.Residual")
# Country: Name of countries
# Happiness.Rank: Rank of the country based on the Happiness Score
# Happiness.Score: Happiness measurement on a scale of 0 to 10
# Whisker.High: Upper confidence interval of happiness score
# Whisker.Low: Lower confidence interval of happiness score
# Economy: The value of all final goods and services produced within a nation in a given year
# Per capita GDP is a measure of the total output of a country that takes the gross domestic product (GDP) and divides it by the number of people in that country. The per capita GDP is especially useful when comparing one country to another, because it shows the relative performance of the countries.
# Family: Importance of having a family
# Life.Expectancy: Importance of health and amount of time prople expect to live
# Freedom: Importance of freedom in each country
# Generosity: The quality of being kind and generous
# Trust: Perception of corruption in a government
# Dystopia.Residual: Plays as a reference
# Deleting unnecessary columns (Whisker.high and Whisker.low)
Happiness <- Happiness[, -c(4,5)]
下一步是在大洲的数据列表中添入另一列。我想要对不同的洲进行工作,以探究不同的因素对得到更高的幸福值是否会有不同的影响效果。亚洲,非洲,北美洲,南美洲,欧洲以及澳洲是数集里的六大洲。接着我将各大洲的这一列移到第二列,因为我认为这样的布局安排会使得数据集更直观。最后, 我将大洲变量的数据类型改成指数型,这样可以简化可视化方面的工作。现在我们可以看到数集的最终结构,它包含了 155 个观察项和 11 个变量。国家和大洲都是指数型变量,幸福等级是整数型变量,剩余变量都是数字型。
# Creating a new column for continents
Happiness$Continent <- NA
Happiness$Continent[which(Happiness$Country %in% c("Israel", "United Arab Emirates", "Singapore", "Thailand", "Taiwan Province of China",
"Qatar", "Saudi Arabia", "Kuwait", "Bahrain", "Malaysia", "Uzbekistan", "Japan",
"South Korea", "Turkmenistan", "Kazakhstan", "Turkey", "Hong Kong S.A.R., China", "Philippines",
"Jordan", "China", "Pakistan", "Indonesia", "Azerbaijan", "Lebanon", "Vietnam",
"Tajikistan", "Bhutan", "Kyrgyzstan", "Nepal", "Mongolia", "Palestinian Territories",
"Iran", "Bangladesh", "Myanmar", "Iraq", "Sri Lanka", "Armenia", "India", "Georgia",
"Cambodia", "Afghanistan", "Yemen", "Syria"))] <- "Asia"
Happiness$Continent[which(Happiness$Country %in% c("Norway", "Denmark", "Iceland", "Switzerland", "Finland",
"Netherlands", "Sweden", "Austria", "Ireland", "Germany",
"Belgium", "Luxembourg", "United Kingdom", "Czech Republic",
"Malta", "France", "Spain", "Slovakia", "Poland", "Italy",
"Russia", "Lithuania", "Latvia", "Moldova", "Romania",
"Slovenia", "North Cyprus", "Cyprus", "Estonia", "Belarus",
"Serbia", "Hungary", "Croatia", "Kosovo", "Montenegro",
"Greece", "Portugal", "Bosnia and Herzegovina", "Macedonia",
"Bulgaria", "Albania", "Ukraine"))] <- "Europe"
Happiness$Continent[which(Happiness$Country %in% c("Canada", "Costa Rica", "United States", "Mexico",
"Panama","Trinidad and Tobago", "El Salvador", "Belize", "Guatemala",
"Jamaica", "Nicaragua", "Dominican Republic", "Honduras",
"Haiti"))] <- "North America"
Happiness$Continent[which(Happiness$Country %in% c("Chile", "Brazil", "Argentina", "Uruguay",
"Colombia", "Ecuador", "Bolivia", "Peru",
"Paraguay", "Venezuela"))] <- "South America"
Happiness$Continent[which(Happiness$Country %in% c("New Zealand", "Australia"))] <- "Australia"
Happiness$Continent[which(is.na(Happiness$Continent))] <- "Africa"
# Moving the continent column's position in the dataset to the second column
Happiness <- Happiness %>% select(Country,Continent, everything())
# Changing Continent column to factor
Happiness$Continent <- as.factor(Happiness$Continent)
str(Happiness)
## 'data.frame': 155 obs. of 11 variables:
## $ Country : Factor w/ 155 levels "Afghanistan",..: 105 38 58 133 45 99 26 100 132 7 ...
## $ Continent : Factor w/ 6 levels "Africa","Asia",..: 4 4 4 4 4 4 5 3 4 3 ...
## $ Happiness.Rank : int 1 2 3 4 5 6 7 8 9 10 ...
## $ Happiness.Score : num 7.54 7.52 7.5 7.49 7.47 ...
## $ Economy : num 1.62 1.48 1.48 1.56 1.44 ...
## $ Family : num 1.53 1.55 1.61 1.52 1.54 ...
## $ Life.Expectancy : num 0.797 0.793 0.834 0.858 0.809 ...
## $ Freedom : num 0.635 0.626 0.627 0.62 0.618 ...
## $ Generosity : num 0.362 0.355 0.476 0.291 0.245 ...
## $ Trust : num 0.316 0.401 0.154 0.367 0.383 ...
## $ Dystopia.Residual: num 2.28 2.31 2.32 2.28 2.43 ...
在这一章节,我们将处理不同的变量来找出它们之间的相关性。
让我们来观察数集中各数字型变量之间的相关性。
########## Correlation between variables
# Finding the correlation between numerical columns
Num.cols <- sapply(Happiness, is.numeric)
Cor.data <- cor(Happiness[, Num.cols])
corrplot(Cor.data, method = 'color')

显然,“幸福等级” 与所有其他所有数字型变量之间呈负相关关系。换句话说就是,幸福等级越低,幸福值就越高,且其他七个因素对幸福的贡献越大。 所以把幸福等级这个因素删除 ,再次观察相关性。
# Create a correlation plot
newdatacor = cor(Happiness[c(4:11)])
corrplot(newdatacor, method = "number")

根据以上的相关系数图,经济水平,平均寿命和家庭支出对幸福感起最关键的作用。对政府的信任感和慷慨度对幸福值的影响最小。
来计算一下平均幸福值和每个洲的其他七个因素的平均值。然后将不同的变量和对应的数值转化到单独的列中。最终,使用 ggplot 来表现不同大陆之间的差异性。

Happiness.Continent <- Happiness %>%
select(-3) %>%
group_by(Continent) %>%
summarise_at(vars(-Country), funs(mean(., na.rm=TRUE)))
# Or we can use aggregate
# aggregate(Happiness[, 4:11], list(Happiness$Continent), mean)
# Melting the "Happiness.Continent" dataset
Happiness.Continent.melt <- melt(Happiness.Continent)
# Faceting
ggplot(Happiness.Continent.melt, aes(y=value, x=Continent, color=Continent, fill=Continent)) +
geom_bar( stat="identity") +
facet_wrap(~variable) + theme_bw() +
theme(axis.text.x = element_text(angle = 90, hjust = 1)) +
labs(title = "Average value of happiness variables for different continents",
y = "Average value")
我们可以看到,澳大利亚在除反乌托邦残余方面之外,几乎所有的方面都达到最高的平均值,接着是欧洲,北美洲和南美洲几乎相同的幸福平均值和剩余七方面的平均值。最后是,亚洲和非洲在所有方面都拿到了最低分。
我们来看每个洲不同变量间的相关性。
corrgram(Happiness %>% select(-3) %>% filter(Continent == "Africa"), order=TRUE,
upper.panel=panel.cor, main="Happiness Matrix for Africa")
在非洲 “幸福值” 和其他变量的相关性:
经济水平 > 家庭状况 > 平均寿命> 反乌托邦残留 > 自由度
幸福值与对政府的信任感之间没有相关性。
幸福值和慷慨度之间呈反相关关系。

corrgram(Happiness %>% select(-3) %>% filter(Continent == "Asia"), order=TRUE,
upper.
=panel.cor, main="Happiness Matrix for Asia")
在亚洲 “幸福值” 和其他变量的相关性:
经济水平 > 家庭状况 > 平均寿命 > 自由度 > 对政府的信任感 > 反乌托邦残留
幸福值和慷慨度之间没有相关性。
corrgram(Happiness %>% select(-3) %>% filter(Continent == "Europe"), order=TRUE,
upper.panel=panel.cor, main="Happiness Matrix for Europe")

在欧洲 “幸福值” 和其他变量的相关性:
自由度 > 对政府的信任感 > 经济水平 > 家庭状况 > 反乌托邦残留 > 平均寿命 > 慷慨度
欧洲出现了慷慨读和幸福值之间最高的相关性。
corrgram(Happiness %>% select(-3) %>% filter(Continent == "North America"), order=TRUE,
upper.panel=panel.cor, main="Happiness Matrix for North America")

在北美洲的 “幸福值” 和其他变量的相关性:
平均寿命 > 经济水平 > 自由度 > 家庭状况 > 反乌托邦残留 > 对政府的信任感
在这里幸福值和慷慨度呈现反相关关系。

corrgram(Happiness %>% select(-3) %>% filter(Continent == "South America"), order=TRUE,
upper.panel=panel.cor, main="Happiness Matrix for South America")
在南美洲的 “幸福值” 和其他变量的相关性:
反乌托邦残留 > 经济水平 > 平均寿命 > 自由度 > 慷慨度 > 对政府的信任感>家庭状况
在南美洲,家庭状况是最不重要的。

我们将会使用散点图,盒式图和小提琴型图来观察幸福值在不同国家的分布,幸福值是如何填充在这些大洲的,并对每个大洲计算平均值和中位数。


####### Happiness score for each continent
gg1 <- ggplot(Happiness,
aes(x=Continent,
y=Happiness.Score,
color=Continent))+
geom_point() + theme_bw() +
theme(axis.title = element_text(family = "Helvetica", size = (8)))
gg2 <- ggplot(Happiness , aes(x = Continent, y = Happiness.Score)) +
geom_boxplot(aes(fill=Continent)) + theme_bw() +
theme(axis.title = element_text(family = "Helvetica", size = (8)))
gg3 <- ggplot(Happiness,aes(x=Continent,y=Happiness.Score))+
geom_violin(aes(fill=Continent),alpha=0.7)+ theme_bw() +
theme(axis.title = element_text(family = "Helvetica", size = (8)))
# Compute descriptive statistics by groups
stable <- desc_statby(Happiness, measure.var = "Happiness.Score",
grps = "Continent")
stable <- stable[, c("Continent","mean","median")]
names(stable) <- c("Continent", "Mean of happiness score","Median of happiness score")
# Summary table plot
stable.p <- ggtexttable(stable,rows = NULL,
theme = ttheme("classic"))
ggarrange(gg1, gg2, ncol = 1, nrow = 2)
ggarrange(gg3, stable.p, ncol = 1, nrow = 2)
正如我们所看到的那样,澳大利亚的幸福值的中位数值最高。欧洲,南美洲,北美洲的中位数值并列第二。亚洲的数值最低,位于非洲以后。 我们可以得到不同大洲的幸福值范围,以及幸福值的集中程度。
通过给不同大洲画散点图,我们可以确定幸福数据与数集中的其他七个因素之间的相关性。

ggplot(subset(Happiness, Happiness$Continent != "Australia"), aes(x = Life.Expectancy, y = Happiness.Score)) +
geom_point(aes(color=Continent), size = 3, alpha = 0.8) +
geom_smooth(aes(color = Continent, fill = Continent),
method = "lm", fullrange = TRUE) +
facet_wrap(~Continent) +
theme_bw() + labs(title = "Scatter plot with regression line")
平均寿命与幸福值的相关性在欧洲,北美洲和亚洲比其他洲更明显。值得一提的是,澳大利亚的数据将不被计入结果,因为澳洲只有两个国家,关于它作出的散点图将不会有任何意义。

ggplot(subset(Happiness, Happiness$Continent != "Australia"), aes(x = Economy, y = Happiness.Score)) +
geom_point(aes(color=Continent), size = 3, alpha = 0.8) +
geom_smooth(aes(color = Continent, fill = Continent),
method = "lm", fullrange = TRUE) +
facet_wrap(~Continent) +
theme_bw() + labs(title = "Scatter plot with regression line")
关于幸福值与经济水平的相关性,我们可以得到于前者很接近的结果。在这一个因素作用下,非洲的结果排在最末位。

ggplot(subset(Happiness, Happiness$Continent != "Australia"), aes(x = Freedom, y = Happiness.Score)) +
geom_point(aes(color=Continent), size = 3, alpha = 0.8) +
geom_smooth(aes(color = Continent, fill = Continent),
method = "lm", fullrange = TRUE) +
facet_wrap(~Continent) +
theme_bw() + labs(title = "Scatter plot with regression line")
自由度与幸福值的相关性,在欧洲和北美洲比其他任何洲都要显著。

ggplot(subset(Happiness, Happiness$Continent != "Australia"), aes(x = Trust, y = Happiness.Score)) +
geom_point(aes(color=Continent), size = 3, alpha = 0.8) +
geom_smooth(aes(color = Continent, fill = Continent),
method = "lm", fullrange = TRUE) +
facet_wrap(~Continent) +
theme_bw() + labs(title = "Scatter plot with regression line")
在非洲,对政府的信任感和幸福值之间几乎没有相关性。

ggplot(subset(Happiness, Happiness$Continent != "Australia"), aes(x = Generosity, y = Happiness.Score)) +
geom_point(aes(color=Continent), size = 3, alpha = 0.8) +
geom_smooth(aes(color = Continent, fill = Continent),
method = "lm", fullrange = TRUE) +
facet_wrap(~Continent) +
theme_bw() + labs(title = "Scatter plot with regression line")
只有欧洲和南美洲对应的回归线的斜率为正。亚洲的回归线是水平的,非洲和北美洲对应的回归线斜率为负。

ggplot(subset(Happiness, Happiness$Continent != "Australia"), aes(x = Family, y = Happiness.Score)) +
geom_point(aes(color=Continent), size = 3, alpha = 0.8) +
geom_smooth(aes(color = Continent, fill = Continent),
method = "lm", fullrange = TRUE) +
facet_wrap(~Continent) +
theme_bw() + labs(title = "Scatter plot with regression line")
对于南美洲而言,随着家庭值增加,幸福值保持不变。

ggplot(subset(Happiness, Happiness$Continent != "Australia"), aes(x = Dystopia.Residual, y = Happiness.Score)) +
geom_point(aes(color=Continent), size = 3, alpha = 0.8) +
geom_smooth(aes(color = Continent, fill = Continent),
method = "lm", fullrange = TRUE) +
facet_wrap(~Continent) +
theme_bw() + labs(title = "Scatter plot with regression line")
针对反乌托邦残留这项因素,所有大洲的表现近乎一致。
以下是观察幸福值与不同变量的相关性,在不同大陆中分布的另一种方式。

#::::::::::::::::::::::::::::Family::::::::::::::::::::::::::::::
sp <- ggscatter(Happiness, x = "Family", y = "Happiness.Score",
color = "Continent", palette = "jco",
size = 3, alpha = 0.6)
# Create box plots of x/y variables
# Box plot of the x variable
xbp <- ggboxplot(Happiness$Family, width = 0.3, fill = "lightgray") +
rotate() +
theme_transparent()
# Box plot of the y variable
ybp <- ggboxplot(Happiness$Happiness.Score, width = 0.3, fill = "lightgray") +
theme_transparent()
# Create the external graphical objects
# called a "grop" in Grid terminology
xbp_grob <- ggplotGrob(xbp)
ybp_grob <- ggplotGrob(ybp)
# Place box plots inside the scatter plot
xmin <- min(Happiness$Family); xmax <- max(Happiness$Family)
ymin <- min(Happiness$Happiness.Score); ymax <- max(Happiness$Happiness.Score)
yoffset <- (1/15)*ymax; xoffset <- (1/15)*xmax
# Insert xbp_grob inside the scatter plot
sp + annotation_custom(grob = xbp_grob, xmin = xmin, xmax = xmax,
ymin = ymin-yoffset, ymax = ymin+yoffset) +
# Insert ybp_grob inside the scatter plot
annotation_custom(grob = ybp_grob,
xmin = xmin-xoffset, xmax = xmin+xoffset,
ymin = ymin, ymax = ymax)

#::::::::::::::::::::::::::::Generosity::::::::::::::::::::::::::::::
sp <- ggscatter(Happiness, x = "Generosity", y = "Happiness.Score",
color = "Continent", palette = "jco",
size = 3, alpha = 0.6)
# Create box plots of x/y variables
# Box plot of the x variable
xbp <- ggboxplot(Happiness$Generosity, width = 0.3, fill = "lightgray") +
rotate() +
theme_transparent()
# Box plot of the y variable
ybp <- ggboxplot(Happiness$Happiness.Score, width = 0.3, fill = "lightgray") +
theme_transparent()
# Create the external graphical objects
# called a "grop" in Grid terminology
xbp_grob <- ggplotGrob(xbp)
ybp_grob <- ggplotGrob(ybp)
# Place box plots inside the scatter plot
xmin <- min(Happiness$Generosity); xmax <- max(Happiness$Generosity)
ymin <- min(Happiness$Happiness.Score); ymax <- max(Happiness$Happiness.Score)
yoffset <- (1/15)*ymax; xoffset <- (1/15)*xmax
# Insert xbp_grob inside the scatter plot
sp + annotation_custom(grob = xbp_grob, xmin = xmin, xmax = xmax,
ymin = ymin-yoffset, ymax = ymin+yoffset) +
# Insert ybp_grob inside the scatter plot
annotation_custom(grob = ybp_grob,
xmin = xmin-xoffset, xmax = xmin+xoffset,
ymin = ymin, ymax = ymax)

#::::::::::::::::::::::::::::Life.Expectancy::::::::::::::::::::::::::::::
sp <- ggscatter(Happiness, x = "Life.Expectancy", y = "Happiness.Score",
color = "Continent", palette = "jco",
size = 3, alpha = 0.6)
# Create box plots of x/y variables
# Box plot of the x variable
xbp <- ggboxplot(Happiness$Life.Expectancy, width = 0.3, fill = "lightgray") +
rotate() +
theme_transparent()
# Box plot of the y variable
ybp <- ggboxplot(Happiness$Happiness.Score, width = 0.3, fill = "lightgray") +
theme_transparent()
# Create the external graphical objects
# called a "grop" in Grid terminology
xbp_grob <- ggplotGrob(xbp)
ybp_grob <- ggplotGrob(ybp)
# Place box plots inside the scatter plot
xmin <- min(Happiness$Life.Expectancy); xmax <- max(Happiness$Life.Expectancy)
ymin <- min(Happiness$Happiness.Score); ymax <- max(Happiness$Happiness.Score)
yoffset <- (1/15)*ymax; xoffset <- (1/15)*xmax
# Insert xbp_grob inside the scatter plot
sp + annotation_custom(grob = xbp_grob, xmin = xmin, xmax = xmax,
ymin = ymin-yoffset, ymax = ymin+yoffset) +
# Insert ybp_grob inside the scatter plot
annotation_custom(grob = ybp_grob,
xmin = xmin-xoffset, xmax = xmin+xoffset,
ymin = ymin, ymax = ymax)

#::::::::::::::::::::::::::::Freedom::::::::::::::::::::::::::::::
sp <- ggscatter(Happiness, x = "Freedom", y = "Happiness.Score",
color = "Continent", palette = "jco",
size = 3, alpha = 0.6)
# Create box plots of x/y variables
# Box plot of the x variable
xbp <- ggboxplot(Happiness$Freedom, width = 0.3, fill = "lightgray") +
rotate() +
theme_transparent()
# Box plot of the y variable
ybp <- ggboxplot(Happiness$Happiness.Score, width = 0.3, fill = "lightgray") +
theme_transparent()
# Create the external graphical objects
# called a "grop" in Grid terminology
xbp_grob <- ggplotGrob(xbp)
ybp_grob <- ggplotGrob(ybp)
# Place box plots inside the scatter plot
xmin <- min(Happiness$Freedom); xmax <- max(Happiness$Freedom)
ymin <- min(Happiness$Happiness.Score); ymax <- max(Happiness$Happiness.Score)
yoffset <- (1/15)*ymax; xoffset <- (1/15)*xmax
# Insert xbp_grob inside the scatter plot
sp + annotation_custom(grob = xbp_grob, xmin = xmin, xmax = xmax,
ymin = ymin-yoffset, ymax = ymin+yoffset) +
# Insert ybp_grob inside the scatter plot
annotation_custom(grob = ybp_grob,
xmin = xmin-xoffset, xmax = xmin+xoffset,
ymin = ymin, ymax = ymax)

#::::::::::::::::::::::::::::Economy::::::::::::::::::::::::::::::
sp <- ggscatter(Happiness, x = "Economy", y = "Happiness.Score",
color = "Continent", palette = "jco",
size = 3, alpha = 0.6)
# Create box plots of x/y variables
# Box plot of the x variable
xbp <- ggboxplot(Happiness$Economy, width = 0.3, fill = "lightgray") +
rotate() +
theme_transparent()
# Box plot of the y variable
ybp <- ggboxplot(Happiness$Happiness.Score, width = 0.3, fill = "lightgray") +
theme_transparent()
# Create the external graphical objects
# called a "grop" in Grid terminology
xbp_grob <- ggplotGrob(xbp)
ybp_grob <- ggplotGrob(ybp)
# Place box plots inside the scatter plot
xmin <- min(Happiness$Economy); xmax <- max(Happiness$Economy)
ymin <- min(Happiness$Happiness.Score); ymax <- max(Happiness$Happiness.Score)
yoffset <- (1/15)*ymax; xoffset <- (1/15)*xmax
# Insert xbp_grob inside the scatter plot
sp + annotation_custom(grob = xbp_grob, xmin = xmin, xmax = xmax,
ymin = ymin-yoffset, ymax = ymin+yoffset) +
# Insert ybp_grob inside the scatter plot
annotation_custom(grob = ybp_grob,
xmin = xmin-xoffset, xmax = xmin+xoffset,
ymin = ymin, ymax = ymax)

#::::::::::::::::::::::::::::Trust::::::::::::::::::::::::::::::
sp <- ggscatter(Happiness, x = "Trust", y = "Happiness.Score",
color = "Continent", palette = "jco",
size = 3, alpha = 0.6)
# Create box plots of x/y variables
# Box plot of the x variable
xbp <- ggboxplot(Happiness$Trust, width = 0.3, fill = "lightgray") +
rotate() +
theme_transparent()
# Box plot of the y variable
ybp <- ggboxplot(Happiness$Happiness.Score, width = 0.3, fill = "lightgray") +
theme_transparent()
# Create the external graphical objects
# called a "grop" in Grid terminology
xbp_grob <- ggplotGrob(xbp)
ybp_grob <- ggplotGrob(ybp)
# Place box plots inside the scatter plot
xmin <- min(Happiness$Trust); xmax <- max(Happiness$Trust)
ymin <- min(Happiness$Happiness.Score); ymax <- max(Happiness$Happiness.Score)
yoffset <- (1/15)*ymax; xoffset <- (1/15)*xmax
# Insert xbp_grob inside the scatter plot
sp + annotation_custom(grob = xbp_grob, xmin = xmin, xmax = xmax,
ymin = ymin-yoffset, ymax = ymin+yoffset) +
# Insert ybp_grob inside the scatter plot
annotation_custom(grob = ybp_grob,
xmin = xmin-xoffset, xmax = xmin+xoffset,
ymin = ymin, ymax = ymax)

#::::::::::::::::::::::::::::Dystopia.Residual::::::::::::::::::::::::::::::
sp <- ggscatter(Happiness, x = "Dystopia.Residual", y = "Happiness.Score",
color = "Continent", palette = "jco",
size = 3, alpha = 0.6)
# Create box plots of x/y variables
# Box plot of the x variable
xbp <- ggboxplot(Happiness$Dystopia.Residual, width = 0.3, fill = "lightgray") +
rotate() +
theme_transparent()
# Box plot of the y variable
ybp <- ggboxplot(Happiness$Happiness.Score, width = 0.3, fill = "lightgray") +
theme_transparent()
# Create the external graphical objects
# called a "grop" in Grid terminology
xbp_grob <- ggplotGrob(xbp)
ybp_grob <- ggplotGrob(ybp)
# Place box plots inside the scatter plot
xmin <- min(Happiness$Dystopia.Residual); xmax <- max(Happiness$Dystopia.Residual)
ymin <- min(Happiness$Happiness.Score); ymax <- max(Happiness$Happiness.Score)
yoffset <- (1/15)*ymax; xoffset <- (1/15)*xmax
# Insert xbp_grob inside the scatter plot
sp + annotation_custom(grob = xbp_grob, xmin = xmin, xmax = xmax,
ymin = ymin-yoffset, ymax = ymin+yoffset) +
# Insert ybp_grob inside the scatter plot
annotation_custom(grob = ybp_grob,
xmin = xmin-xoffset, xmax = xmin+xoffset,
ymin = ymin, ymax = ymax)
在可视化的最后一部分,让我们作一些特别的图。 我必须声明,我并不支持三维图或任何特别的图,不过我们可以通过它们增加一些趣味性!

scatter3D(Happiness$Freedom, Happiness$Life.Expectancy, Happiness$Happiness.Score, phi = 0, bty = "g",
pch = 20, cex = 2, ticktype = "detailed",
main = "Happiness data", xlab = "Freedom",
ylab ="Life.Expectancy", zlab = "Happiness.Score")
根据这个图可以得知,平均寿命越高,自由度越强,幸福值就会越高。

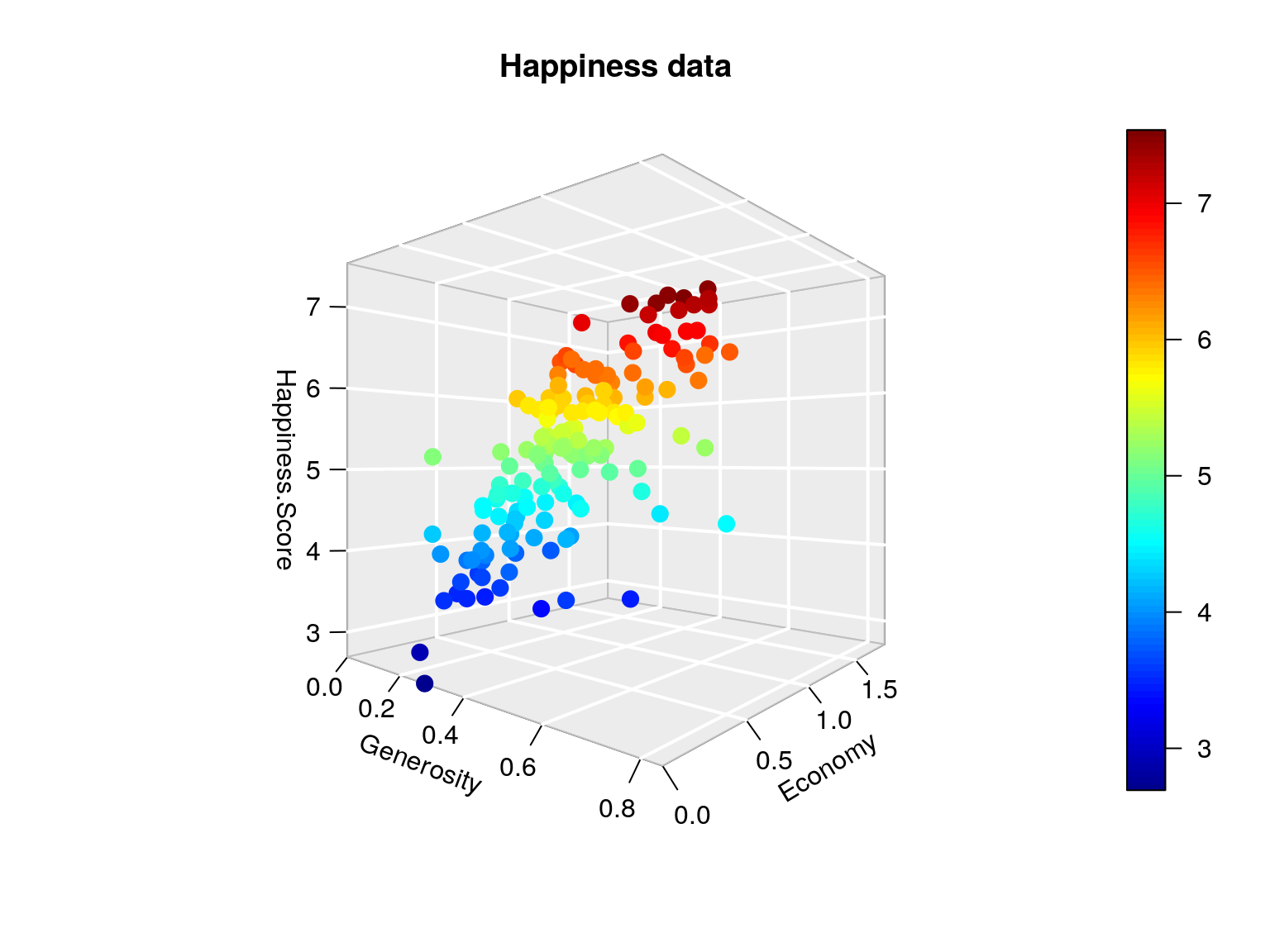
scatter3D(Happiness$Generosity, Happiness$Economy, Happiness$Happiness.Score, phi = 0, bty = "g",
pch = 20, cex = 2, ticktype = "detailed",
main = "Happiness data", xlab = "Generosity",
ylab ="Economy", zlab = "Happiness.Score")
经济水平越高,慷慨度越低,会导致更高的幸福水平。

scatter3D(Happiness$Trust, Happiness$Freedom, Happiness$Happiness.Score, phi = 0, bty = "g",
pch = 20, cex = 2, ticktype = "detailed",
main = "Happiness data", xlab = "Trust",
ylab ="Freedom", zlab = "Happiness.Score")
总体而言,对政府的信任感对于取得更高的幸福值并不会起到关键作用。不过我们可以看到,对于那些自由度很重要并且幸福值超过 7 分的国家来说,信任感很重要。

scatter3D(Happiness$Family, Happiness$Economy, Happiness$Happiness.Score, phi = 0, bty = "g",
pch = 20, cex = 2, ticktype = "detailed",
main = "Happiness data", xlab = "Trust",
ylab ="Economy", zlab = "Happiness.Score")
对于那些幸福值低于 5 分的国家通过相关性曲线可以看出,随着经济水平的提高和幸福值的增加,信任感保持不变。而在幸福值 5 分这一点之后,信任感对幸福值增加的影响逐渐增大。
在这一章,我们将运用不同的机器学习算法来预测幸福值。首先,我们需要将数集分成训练组和测试组。我们的因变量是幸福值,自变量分别是家庭状况,经济水平,信任感,自由度,慷慨度和反乌托邦残留。
# Splitting the dataset into the Training set and Test set
# install.packages('caTools')
library(caTools)
set.seed(123)
dataset <- Happiness[4:11]
split = sample.split(dataset$Happiness.Score, SplitRatio = 0.8)
training_set = subset(dataset, split == TRUE)
test_set = subset(dataset, split == FALSE)
多元线性回归
# Fitting Multiple Linear Regression to the Training set
regressor_lm = lm(formula = Happiness.Score ~ .,
data = training_set)
summary(regressor_lm)
##
## Call:
## lm(formula = Happiness.Score ~ ., data = training_set)
##
## Residuals:
## Min 1Q Median 3Q Max
## -5.907e-04 -2.008e-04 -1.600e-07 2.510e-04 4.855e-04
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 1.701e-04 1.509e-04 1.127 0.262
## Economy 1.000e+00 1.300e-04 7690.839 <2e-16 ***
## Family 9.999e-01 1.253e-04 7981.804 <2e-16 ***
## Life.Expectancy 9.997e-01 2.122e-04 4711.655 <2e-16 ***
## Freedom 9.999e-01 2.245e-04 4453.253 <2e-16 ***
## Generosity 1.000e+00 2.310e-04 4330.040 <2e-16 ***
## Trust 9.997e-01 3.335e-04 2997.191 <2e-16 ***
## Dystopia.Residual 1.000e+00 5.452e-05 18343.021 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.0002848 on 116 degrees of freedom
## Multiple R-squared: 1, Adjusted R-squared: 1
## F-statistic: 2.689e+08 on 7 and 116 DF, p-value: < 2.2e-16
结果表明,所有的自变量都有重要的作用且校准的 R 的平方为 1!就如我们探讨的那样,自变量与因变量之间存在明显的线性关系。同样,我要强调自变量之和等于因变量,也就是幸福值。这就证明了校准的 R 的平方为 1 这个结论。因此,推测多元线性回归将可以 100% 正确的预测幸福值。
####### Predicting the Test set results
y_pred_lm = predict(regressor_lm, newdata = test_set)
Pred_Actual_lm <- as.data.frame(cbind(Prediction = y_pred_lm, Actual = test_set$Happiness.Score))
gg.lm <- ggplot(Pred_Actual_lm, aes(Actual, Prediction )) +
geom_point() + theme_bw() + geom_abline() +
labs(title = "Multiple Linear Regression", x = "Actual happiness score",
y = "Predicted happiness score") +
theme(plot.title = element_text(family = "Helvetica", face = "bold", size = (15)),
axis.title = element_text(family = "Helvetica", size = (10)))
gg.lm

和预期一样,实际和预测的对比图证明了模型的准确性。
SVR(支持向量回归)

# Fitting SVR to the dataset
library(e1071)
regressor_svr = svm(formula = Happiness.Score ~ .,
data = dataset,
type = 'eps-regression',
kernel = 'radial')
# Predicting a new result
y_pred_svr = predict(regressor_svr, newdata = test_set)
Pred_Actual_svr <- as.data.frame(cbind(Prediction = y_pred_svr, Actual = test_set$Happiness.Score))
Pred_Actual_lm.versus.svr <- cbind(Prediction.lm = y_pred_lm, Prediction.svr = y_pred_svr, Actual = test_set$Happiness.Score)
gg.svr <- ggplot(Pred_Actual_svr, aes(Actual, Prediction )) +
geom_point() + theme_bw() + geom_abline() +
labs(title = "SVR", x = "Actual happiness score",
y = "Predicted happiness score") +
theme(plot.title = element_text(family = "Helvetica", face = "bold", size = (15)),
axis.title = element_text(family = "Helvetica", size = (10)))
gg.svr
通过支持向量回归预测出的幸福值具有相当高的准确性。
决策树回归
# Fitting Decision Tree Regression to the dataset
library(rpart)
regressor_dt = rpart(formula = Happiness.Score ~ .,
data = dataset,
control = rpart.control(minsplit = 10))
# Predicting a new result with Decision Tree Regression
y_pred_dt = predict(regressor_dt, newdata = test_set)
Pred_Actual_dt <- as.data.frame(cbind(Prediction = y_pred_dt, Actual = test_set$Happiness.Score))
gg.dt <- ggplot(Pred_Actual_dt, aes(Actual, Prediction )) +
geom_point() + theme_bw() + geom_abline() +
labs(title = "Decision Tree Regression", x = "Actual happiness score",
y = "Predicted happiness score") +
theme(plot.title = element_text(family = "Helvetica", face = "bold", size = (15)),
axis.title = element_text(family = "Helvetica", size = (10)))
gg.dt

看起来对于这个数集,决策树回归不是一个好的选择。我们来看看这个树状图。

# Plotting the tree
library(rpart.plot)
prp(regressor_dt)
随机森林回归

# Fitting Random Forest Regression to the dataset
library(randomForest)
set.seed(1234)
regressor_rf = randomForest(x = dataset[-1],
y = dataset$Happiness.Score,
ntree = 500)
# Predicting a new result with Random Forest Regression
y_pred_rf = predict(regressor_rf, newdata = test_set)
Pred_Actual_rf <- as.data.frame(cbind(Prediction = y_pred_rf, Actual = test_set$Happiness.Score))
gg.rf <- ggplot(Pred_Actual_rf, aes(Actual, Prediction )) +
geom_point() + theme_bw() + geom_abline() +
labs(title = "Random Forest Regression", x = "Actual happiness score",
y = "Predicted happiness score") +
theme(plot.title = element_text(family = "Helvetica", face = "bold", size = (15)),
axis.title = element_text(family = "Helvetica", size = (10)))
gg.rf
随机森林回归得到的结果没有支持向量回归那么好,不过比决策树回归要好的多。
神经网络

# Fitting Neural Net to the training set
library(neuralnet)
nn <- neuralnet(Happiness.Score ~ Economy + Family + Life.Expectancy + Freedom + Generosity + Trust + Dystopia.Residual,
data=training_set,hidden=10,linear.output=TRUE)
plot(nn)
predicted.nn.values <- compute(nn,test_set[,2:8])
Pred_Actual_nn <- as.data.frame(cbind(Prediction = predicted.nn.values$net.result, Actual = test_set$Happiness.Score))
gg.nn <- ggplot(Pred_Actual_nn, aes(Actual, V1 )) +
geom_point() + theme_bw() + geom_abline() +
labs(title = "Neural Net", x = "Actual happiness score",
y = "Predicted happiness score") +
theme(plot.title = element_text(family = "Helvetica", face = "bold", size = (15)),
axis.title = element_text(family = "Helvetica", size = (10)))
gg.nn
神经网络是仅次于多元线性回归的最好的预测算法。事实上,通过神经网络模型预测幸福值,其准确性接近 100% 。我们对多元线性回归和神经网络模型计算均方差。
MSE.lm <- sum((test_set$Happiness.Score - y_pred_lm)^2)/nrow(test_set)
MSE.nn <- sum((test_set$Happiness.Score - predicted.nn.values$net.result)^2)/nrow(test_set)
print(paste("Mean Squared Error (Multiple Linear Regression):", MSE.lm))
## [1] "Mean Squared Error (Multiple Linear Regression): 0.0000000912868493258188"
print(paste("Mean Squared Error (Neural Net):", MSE.nn))
## [1] "Mean Squared Error (Neural Net): 0.00146160413611951"
和预期一样,多元线性回归的均方差要小于神经网络模型的。
实际结果与通过不同的机器学习算法的预测结果作对比
再次观察预测出的结果,来直观感受预测结果的准确性。
ggarrange(gg.lm, gg.svr, gg.dt, gg.rf, gg.nn, ncol = 2, nrow = 3)

多元线性回归和神经网络的结果最好,预测也几乎相同。支持向量回归和随机森林回归的预测准确性占据第二位。最后是决策树算法,对预测幸福值这项工作它的结果是最糟糕的。
雷锋网字幕组编译。


正在生成分享图...
 卢洁萍
卢洁萍