雷锋网 AI 科技评论按:本文作者为阿德莱德大学助理教授吴琦,他在为雷锋网 AI 科技评论投递的独家稿件中回顾了他从跨领域图像识别到 Vision-to-Language 相关的研究思路,如今正将研究领域延伸到与 Action 相关的工作。雷锋网 AI 科技评论对文章做了不改动原意的编辑。
大家好,我叫吴琦,目前在阿德莱德大学担任讲师(助理教授)。2014 年博士毕业之后,有幸加入澳大利亚阿德莱德大学(University of Adelaide)开始为期 3 年的博士后工作。由于博士期间主要研究内容是跨领域图像识别,所以博士后期间,原本希望能够继续开展与跨领域相关方面的研究。但是,在与博士后期间的导师 Anton van den Hengel、沈春华教授讨论之后,决定跳出基于图像内部的跨领域研究,而展开图像与其他外部领域的跨领域研究。恰逢 2015 年 CVPR 有数篇 image captioning 的工作,其中最有名的当属 Andrej Karpathy 的 NeuralTak 和 Google 的 Show and Tell,同时 2015 年的 MS COCO Image Captioning Challenge 也得到了大量的关注。所以当时就决定开始研究与 Vision-to-Language 相关的跨领域问题。后来也在这个问题上越走越深,近三年在 CVPR,AAAI,IJCAI,TPAMI 等顶级会议与期刊上,先后发表了 15 篇与 vision-language 相关的论文,近期我们又将这个问题延伸到了与 Action 相关的领域,开启了一个全新的方向。接下来我就介绍一下我的一些研究思路,工作,以及我对这个领域的一些想法。
我们 15 年第一个研究的问题是围绕 image captioning 展开的,当时这个方向的主流模型是基于 CNN-RNN 框架的,即输入一张图像,先用一个 pre-trained 的 CNN 去提取图像特征,然后,将这些 CNN 特征输入到 RNN,也就是递归神经网络当中去生成单词序列。这种模型表面上看起来非常吸引人,依赖于强大的深度神经网络,能够用 end-to-end 的方式学习到一个从图像到语言(vision2language)的直接对应关系,但忽略了一个重要的事实是,图像和语言之间,其实是存在鸿沟的。虽然我们用神经网络将图像空间和语言空间 embed 在同一个空间当中,但直觉上告诉我,这两个空间应该需要一个共同的 sub-space 作为桥梁来连接。于是我们想到了 attributes,一种图像和语言都拥有的特征。于是,基于上面提到的 CNN-RNN 结构,我们多加了一个 attributes prediction layer。当给定一张图像,我们先去预测图像当中的各种 attributes(我们的 attributes 定义是广义的,包括物体名称,属性,动作,形容词,副词,情绪等等),然后再将这些 attributes 代替之前的 CNN 图像特征(如图 1),输入到 RNN 当中,生成语句。

图 1:从图像到词语再到语句的 image captioning 模型
我们发现这个简单的操作使我们的 image captioning 模型得到了大幅度的提升(见图 2),并使得我们在 15 年 12 月的 MS COCO Image Captioning Challenge Leader Board 上在多项测评中排名第一(见图 3)。论文后来也被 CVPR 2016 接收,见论文 [1]。

图 2:Image captioning with predicted attributes

图 3: Our results (Q.Wu) on MS COCO Image Captioning Challenge Leader Board, Dec/2015
看到 attributes 在 image captioning 上的作用之后,我们开始考虑,相同的思路是否可以扩展到更多的 vision-and-language 的问题上?毕竟, vision 和 language 之间的 gap 是客观存在的,而 attributes 能够有效地缩小这种 gap。于是我们尝试将相同的框架运用在了 visual question answering(VQA)上(见图 4),也取得了非常好的效果。相关结果已发表于 TPAMI,见论文 [2].

图 4:Adding intermediate attributes layer in VQA
然而,VQA 与其他 vision-to-language 不同的是,当它需要一个机器去回答一个关于图片内容的问题的时候,机器不仅需要能够理解图像以及语言信息,还要能够具有一定的常识,比如,如图 5 左边所示,问题是图中有几只哺乳动物。那么回答这个问题,我们不仅需要机器能够「看」到图中有狗,猫,鸟,还需要机器能够「知道」狗和猫是哺乳动物,而鸟不是,从而「告诉」我们正确答案是 2.

图 5:Common-sense required questions
于是,我们就自然想到了将知识图谱(knowledge-base)引入到 VQA 当中,帮助我们回答类似的问题。那么该如何连接起图像内容和 knowledge base 呢?我们的 attributes 这时候就又发挥了作用。我们先将图像当中的 attributes 提取出来,然后用这些 attributes 去 query knowledge base(DBpedia),去找到相关的知识,然后再使用 Doc2Vec 将这些知识信息向量化,再与其他信息一起,输入到 lstm 当中,去回答问题。我们的这个框架(见图 6)在 VQA 数据集上取得非常好的表现,相关论文结果已发表于 CVPR 2016,见论文 [3].

图 6:VQA model with knowledge base
虽然我们上面提出的框架解决了回答关于「common sense」的问题的挑战,但是我们发现在 VQA 当中还有两个重要的局限:
CV doesn't help a lot
-Only CNN features are used
-CNN is simply trained on object classification
-VQA requires multiple CV tasks
No reasons are given
-Image + Question -> Answer mapping
-Providing reasons is important, e.g. Medical service, Defense.
第一个局限指的是, computer vision 其实在 VQA 当中的作用太小了,我们仅仅是使用 CNN 去对图片当中的物体等内容进行理解。而一个基于图片的问题,可能会问物体之间的关系,物体中的文字等等,而这其实是需要多种的计算机视觉算法来解决的。
第二个局限指的是,在回答问题的过程当中,我们没有办法给出一个合理的解释。而「可解释性」恰恰是近几年来大家都很关注的一个问题。如果我们在回答问题的过程当中,还能够提供一个可理解的原因,将是非常有帮助的。
那么基于上面这两点,我们就提出了一种新的 VQA 结构,我们称之为 VQA Machine。这个模型可以接收多个 computer vision 算法输出的结果,包括 object detection,attributes prediction,relationship detection 等等,然后将这些信息进行融合,得出答案。同时,我们的 VQA Machine 除了输出答案之外,还可以输出原因。在这个模型中,我们首先将问题从三个 level 来 encode。在每个 level,问题的特征与图像还有 facts 再一起 jointly embed 在一个空间当中,通过一个 co-attention model。这里的 facts 是一系列的,利用现有计算机视觉模型所提取出的图像信息。最后,我们用一个 MLP 去预测答案,基于每一层的 co-attention model 的输出。那么回答问题的原因是通过对加权后的 facts 进行排序和 re-formulating 得到的(见图 7)。

图 7:VQA Machine Framework
我们的这个模型在 VQA 数据集上取得了 state-of-art 的表现(见表 1),更重要的是,它在回答问题的同时,能够给出对应的解释,这是其他的 VQA 模型所做不到的。图 8 给出了一些我们模型产生的结果。论文已经发表在 CVPR 2017,见论文 [4].

表 1:Single model performance on the VQA-real test set

图 8:VQA Machine 结果,问题中带颜色的词表示 top-3 的权重。代表了这个词在回答这个问题时的重要程度。图像当中高亮的区域表示图像当中 attention weights。颜色越深的区域说明这个区域对回答问题更重要。最后是我们模型生成的回答问题的原因。
既然我们知道了 knowledge 和 reasoning 对 VQA 都很重要,那么怎么将它们两个结合在一起,同时能够进行 explicit reasoning(显示推理)呢?所谓 explicit reasoning,就是在回答问题的过程当中,能够给出一条可追溯的逻辑链。于是我们又提出了 Ahab,一种全新的能够进行显式推理的 VQA 模型。在这个模型当中,与以往直接把图像加问题直接映射到答案不同,Ahab 首先会将问题和图像映射到一个 KB query,也就是知识图谱的请求,从而能够接入到成千上万的知识库当中。另外,在我们的模型当中,答案是 traceable 的,也就是可以追踪的,因为我们可以通过 query 在知识图谱当中的搜索路径得到一个显式的逻辑链。
图 9 展示了我们这一方法。我们的方法可以分成两部分。
首先在第一部分,我们会检测到图像当中的相关概念,然后将他们连接到一个知识图谱当中,形成一个大的 graph,我们把这个过程称为 RDF graph construction process。
在第二步,一个自然语言式的问题会被首先处理成一个合适的 query,这个 query 会去请求上一步当中建立好的图。这个 query 可能会需要到多步的推理过程,而这个 query 对应的 response 则会形成对应问题的答案。

图 9:Our Ahab VQA model
最近我们又建立了一个新的 VQA 数据集叫做 fact-based VQA,就是基于事实的 VQA。我们之前的基于 explicit reasoning 的数据集只能接受固定的模板式的问题,而新的 FVQA 数据集提供了开放式的问题。除此之外,对每一对问题-答案,我们额外提供了一个 supporting fact。所以在回答问题的时候,我们不仅需要机器回答出这个问题,而且还需要它能够提供关于这个回答的 supporting fact。图 10 展示了我们 Ahab 和 FVQA 模型和数据的一些例子。相关数据与结果分别发表于 IJCAI 2017 和 TPAMI,见论文 [5,6]

图 10: Ahab and FVQA datasets and results
从 VQA 可以衍生出很多新的问题,Visual Dialog(视觉对话)就是其中一个。与 VQA 只有一轮问答不同的是,视觉对话需要机器能够使用自然的,常用的语言和人类维持一个关于图像的,有意义的对话。与 VQA 另外一个不同的地方在于,VQA 的回答普遍都很简短,比如说答案是 yes/no, 数字或者一个名词等等,都偏机器化。而我们希望 visual dialog 能够尽量的生成偏人性化的数据。比如图 11 所示,面对同样的问题,偏人类的回答信息量更丰富,也更自然,同时能够关注到已经发生的对话,并且引出接下来要发生的对话。而偏机器的回应,就非常的古板,基本没法引出下面的对话。

图 11:Human-like vs, Machine-like
于是我们提出了一个基于 GAN(生成对抗网络) 的方法 (图 12),来帮助模型生成更加符合人类预期的回答。我们左边的生成网络是使用了一个 co-attention,也就是一个联合注意力模型,来联合的使用图像,对话历史来生成新的对话,然后我们将生成的对话以及从生成模型中得出的 attention,一起,送入到一个区别模型当中,去区别对话为人工产生还是自动生成,然后通过 reward 的形式,去鼓励模型生成更加符合人类的对话。

图 12:Dialog Generation via GAN

图 13: Co-attention model
这项工作中,我们使用了一个 co-attention 的模型,来融合来自各个模态的信息,相同的模型也用在我们上面提到的 VQA-machine 当中。在一个 co-attention 模型当中,我们使用两种特征去 attend 另外一种特征,从而进行有效地特征选择。这种 attend 模式会以 sequential 的形式,运行多次,直到每个输入特征,均被另外两个特征 attend 过。该论文 [7] 被 CVPR2018 接受,大会 oral。

图 14:Visual Dialog 结果对比
前面简单介绍了一些我们在 vision-language 方向上的工作,可以看到,两者的结合无论在技术上还是应用上,都非常的有意义。然而,对于人工智能(AI)而言,这只是一小步。真正的人工智能,除了能够学习理解多种模态的信息,还应该能与真实环境进行一定程度的交互,可以通过语言,也可以通过动作,从而能够改变环境,帮助人类解决实际问题。那么从今年开始,我们开始将 action 也加入进来,进行相关的研究。
我为此提出了一个 V3A 的概念,就是 Vision,Ask,Answer and Act(如图 15),在这个新的体系当中,我们以视觉(Vision)作为中心,希望能够展开提问(Ask),回答(Answer),行动(Act)等操作。这样,我们不仅能够得到一个可训练的闭环,还将很多之前的 vision-language 的任务也融合了进来。比如在 Ask 这一端,我们可以有 Visual Question Generation,image captioning 这样的任务,因为他们都是从图像到语言的生成。在 Answer 这一端,我们可以有 VQA,Visual Dialog 这样需要机器能够产生答案的模型。在 Act 端,我们也有会有一些很有意思的任务,比如 referring expression 和 visual navigation。那么我们在今年的 CVPR2018 上,在这两个方面,都有相关的工作。

图 15:V3A 框架
首先谈一下 referring expression,也叫做 visual grounding,它需要机器在接受一张图片和一个 query(指令)之后,「指」出图片当中与这个 query 所相关的物体。为了解决这个问题,我们提出了一个统一的框架,ParalleL AttentioN(PLAN)网络,用于从可变长度的自然描述中发现图像中的对象。自然描述可以从短语到对话。PLAN 网络有两个注意力机制,将部分语言表达与全局可视内容以及候选目标直接相关联。此外,注意力机制也是重复迭代的,这使得推理过程变的可视化和可解释。来自两个注意力的信息被合并在一起以推理被引用的对象。这两种注意机制可以并行进行训练,我们发现这种组合系统在不同长度语言输入的几个标准数据集上的性能优于现有技术,比如 RefCOCO,RefCOCO +和 GuessWhat 数据集。论文见 [8]。我们还提出了一个基于 co-attention 的模型,论文见 [9]。

图 16:ParalleL AttentioN(PLAN)Network
接下来再给大家介绍一篇我们关于 Visual Navigation 的文章 [10],该论文也被 CVPR2018 接受,由于 topic 比较新颖,也被大家关注。这篇文章叫「Vision-and-Language Navigation: Interpreting visually-grounded navigation instructions in real environments」。我们这篇文章想要解决的一个问题就是如何使用一段复杂的人类语言命令,去指导机器人在模拟的真实环境当中,去完成对应的动作和任务。
那么在这篇文章当中,我们首先提出了一个 Matterport3D Simulator。这个 simulator 是一个大规模的可基于强化学习的可交互式环境。在这个 simulator 的环境当中,我们使用了 10800 张 densely-sampled 360 度全景加深度图片,也就是说可以提供到点云级别。然后我们总共有 90 个真实世界的室内场景。那么与之前一些虚拟环境的 simulator 而言,我们和这个新的 simulator 更具有挑战性,同时更接近于实际。图 17 展示了我们的一个真实场景以及机器人(agent)可移动的路线。

图 17:Example navigation graph for a partial floor of one building-scale scene in the Matterport3D Simulator. Navigable paths between panoramic viewpoints are illustrated in blue. Stairs can also be navigated to move between floors.
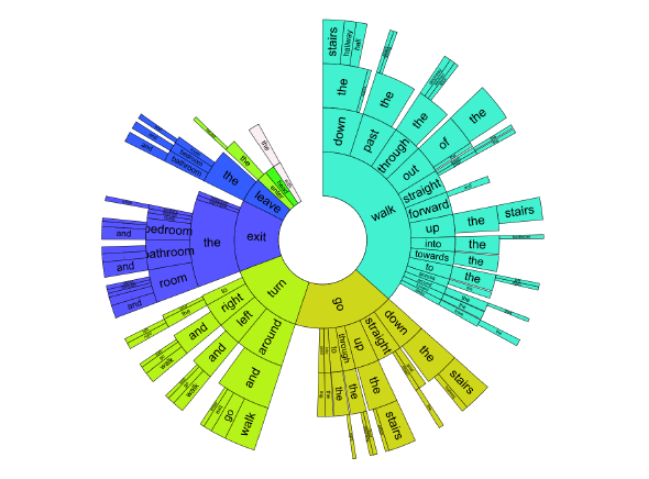
基于我们的 Matterport3D Simulator,我们又收集了一个 Room-to-Room (R2R) 的数据集,在这个数据集当中,我们收集了 21567 条 navigation instruction(导航指令),平均长度为 29 个单词。每一条指令都描述了一条跨越多个房间的指令。如图 18 所示。图 19 显示了我们导航指令的用词分布。
那么除了上述 simulator 和数据,我们这篇文章还提出了一个 sequence-to-sequence 的模型,改模型与 VQA 模型非常类似,只是将输出动作作为了一种 sequence,用 LSTM 来预测。我们还加入了诸如 teacher-forcing,student-forcing 等变种,取得了更好的效果。我们接下来会继续扩充数据,并保留测试集,提供公平的测试平台,每年举行相关的比赛。请大家关注!

图 18:Room-to-Room (R2R) navigation task. We focus on executing natural language navigation instructions in previously unseen real-world buildings. The agent's camera can be rotated freely. Blue discs indicate nearby (discretized) navigation options

图 19:Distribution of navigation instructions based on their first four words. Instructions are read from the center outwards. Arc lengths are proportional to the number of instructions containing each word. White areas represent words with individual contributions too small to show.
人工智能是一个非常复杂的整体的系统,涉及到视觉,语言,推理,学习,动作等等方面,那么计算机视觉作为人工智能领域内的一个方向,除了关注经典的纯视觉的问题(比如图像识别,物体分类等),也应该关注如何与其他领域相结合来实现更高难度的任务与挑战。视觉与语言(vision-language)的结合就是一个非常好的方向,不仅引出了像 image captioning 和 VQA 这种有意思的问题,还提出了很多技术方面的挑战,比如如何融合多领域多维度的信息。我们进一步将 vision-language 引入到了 action 的领域,希望机器能够具有问(Ask),答(Answer)和作(Act)的能力,实质上就是希望机器能够理解和处理视觉信息,语言信息,并输出对应的动作信息,以完成更高程度的跨域信息融合。

图 20:Further plans
接下来我们将继续在 vision-language-action 的方向上做更多的探索,目前的 room-to-room navigation 数据集只是第一步,我们接下来将基于我们的 Matterport3D Simulator, 进一步提出 Visible Object Localization,Hidden Object Localization 和 Ask-to-find 的任务(如图 20),希望 agent 能够通过基于语言的指令,在场景中导航定位到可见(Visible)的物体,隐藏(Hidden)的物体,以及当指令存在歧义时,能够提出问题,消除歧义,从而进一步完成任务。
[1] Qi Wu, Chunhua Shen, Anton van den Hengel, Lingqiao Liu, Anthony Dick. What Value Do Explicit High Level Concepts Have in Vision to Language Problems?. IEEE Conference on Computer Vision and Pattern Recognition (CVPR'16), Las Vegas, Nevada, US, Jun, 2016.
[2] Qi Wu, Chunhua Shen, Peng Wang, Anthony Dick, Anton van den Hengel, Image Captioning and Visual Question Answering Based on Attributes and Their Related External Knowledge. IEEE Transaction on Pattern Analysis and Machine Intelligence (TPAMI), Volume:40 Issue:6. 2018.
[3] Qi Wu, Peng Wang, Chunhua Shen, Anton van den Hengel, Anthony Dick. Ask Me Anything: Free-form Visual Question Answering Based on Knowledge from External Sources. IEEE Conference on Computer Vision and Pattern Recognition (CVPR'16), Las Vegas, Nevada, US, Jun, 2016.
[4] Peng Wang*, Qi Wu*, Chunhua Shen, Anton van den Hengel. The VQA-Machine: Learning How to Use Existing Vision Algorithms to Answer New Questions. IEEE Conference on Computer Vision and Pattern Recognition (CVPR'17), Honolulu, Hawaii, US, Jul, 2017.
[5] Peng Wang*, Qi Wu*, Chunhua Shen, Anton van den Hengel, Anthony Dick. Explicit Knowledge-based Reasoning for Visual Question Answering. International Joint Conference on Artificial Intelligence (IJCAI'17), Melbourne, Australia, Aug, 2017.
[6] Peng Wang*, Qi Wu*, Chunhua Shen, Anton van den Hengel, Anthony Dick. FVQA: Fact-based Visual Question Answering. IEEE Transaction on Pattern Analysis and Machine Intelligence (TPAMI), In Press, 2018.
[7] Qi Wu, Peng Wang, Chunhua Shen, Ian Reid, Anton van den Hengel. Are You Talking to Me? Reasoned Visual Dialog Generation through Adversarial Learning. IEEE Conference on Computer Vision and Pattern Recognition (CVPR'18), Salt Lake City, Utah, US, Jun, 2018. (Accepted 19/2/18). [Oral]
[8] Bohan Zhuang*, Qi Wu*, Chunhua Shen, Ian Reid, Anton van den Hengel. Parallel Attention: A Unified Framework for Visual Object Discovery through Dialogs and Queries. IEEE Conference on Computer Vision and Pattern Recognition (CVPR'18), Salt Lake City, Utah, US, Jun, 2018.
[9] Chaorui Deng*, Qi Wu*, Fuyuan Hu, Fan Lv, Mingkui Tan, Qingyao Wu. Visual Grounding via Accumulated Attention. IEEE Conference on Computer Vision and Pattern Recognition (CVPR'18), Salt Lake City, Utah, US, Jun, 2018.
[10] Peter Anderson, Qi Wu, Damien Teney, Jake Bruce, Mark Johnson, Niko Snderhauf, Ian Reid, Stephen Gould, Anton van den Hengel. Vision-and-Language Navigation: Interpreting visually-grounded navigation instructions in real environments. IEEE Conference on Computer Vision and Pattern Recognition (CVPR'18), Salt Lake City, Utah, US, Jun, 2018.
[11] Qi Wu, Damien Teney, Peng Wang, Chunhua Shen, Anthony Dick, Anton van den Hengel. Visual question answering: A survey of methods and datasets. Computer Vision and Image Understanding (CVIU), v. 163, p. 21-40, 2017.
[12] Damien Teney, Qi Wu, Anton van den Hengel. Visual Question Answering: A Tutorial. IEEE Signal Processing Magazine, v. 34, n. 6, p. 63-75, 2017
[13] Yan Huang, Qi Wu, Liang Wang. Learning Semantic Concepts and Order for Image and Sentence Matching. IEEE Conference on Computer Vision and Pattern Recognition (CVPR'18), Salt Lake City, Utah, US, Jun, 2018.
[14] Chao Ma, Chunhua Shen, Anthony Dick, Qi Wu, Peng Wang, Anton van den Hengel, Ian Reid. Visual Question Answering with Memory-Augmented Networks. IEEE Conference on Computer Vision and Pattern Recognition (CVPR'18), Salt Lake City, Utah, US, Jun, 2018.
[15] Bohan Zhuang*, Qi Wu*, Ian Reid, Chunhua Shen, Anton van den Hengel. HCVRD: a benchmark for largescale Human-Centered Visual Relationship Detection. AAAI Conference on Artificial Intelligence (AAAI'18), New Orleans, Louisiana, US, Feb, 2018. [Oral]

吴琦现任澳大利亚阿德莱德大学(University of Adelaide)讲师(助理教授),澳大利亚机器视觉研究中心(Australia Centre for Robotic Vision)任 Associate Investigator(课题副组长)。在加入阿德莱德大学之前,担任澳大利亚视觉科技中心(Australia Centre for Visual Technologies)博士后研究员。分别于 2015 年,2011 年于英国巴斯大学(University of Bath)取得博士学位和硕士学位。他的主要研究方向包括计算机视觉,机器学习等,目前主要研究基于 vision-language 的相关课题,包括 image captioning,visual question answering,visual dialog 等。目前已在 CVPR,ICCV,ECCV,IJCAI,AAAI,TPAMI,TMM 等会议与刊物上发表论文数十篇。担任 CVPR,ECCV,TPAMI,IJCV,TIP,TNN,TMM 等会议期刊审稿人。

正在生成分享图...
 nebula
nebula