
F, B, Alpha Matting
使用一种基于符号化方法的LSTM网络进行时间序列预测
RevealNet:窥探RGB-D扫描场景中的每个物体
BERT还不足以称之为知识库:无监督问答任务中BERT对事实性的知识和基于名称的推理学习能力对比
实时语义立体匹配
论文名称:F, B, Alpha Matting
作者:Marco Forte /François Pitié
发表时间:2020/3/17
论文链接:https://paper.yanxishe.com/review/14460?from=leiphonecolumn_paperreview0331
推荐原因
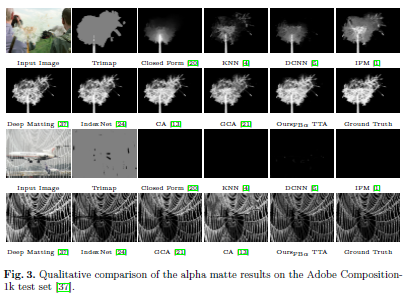
本文已经被提交到ECCV2020。Image Matting是众多图像编辑应用中的一个关键技术,其需要将对象从图片分割出来并估计其不透明蒙版。基于深度学习的方法也取得了很大的进展,但大多数现有网络仅预测alpha遮罩,需要借助后处理方法来恢复透明区域中的原始前景色和背景色。虽然最近也有两种新的方法来同时估计前景色,但其需要大量的计算和存储成本。
本文提出了对Matting网络的低成本修改,使其能够同时预测前景色和背景色。作者研究了训练方式的变化,并探索了大量现有的和新颖的损失函数用于联合训练。文章方法在Adobe Composition-1k数据集上实现了alpha遮罩和复合颜色质量的最先进表现,并在在线评价系统alphamatting.com上取得目前第一的排名。

论文名称:Time Series Forecasting Using LSTM Networks: A Symbolic Approach
作者:Steven Elsworth and Stefan Guttel
发表时间:2020/3/12
论文链接:https://paper.yanxishe.com/review/14428?from=leiphonecolumn_paperreview0331
推荐原因
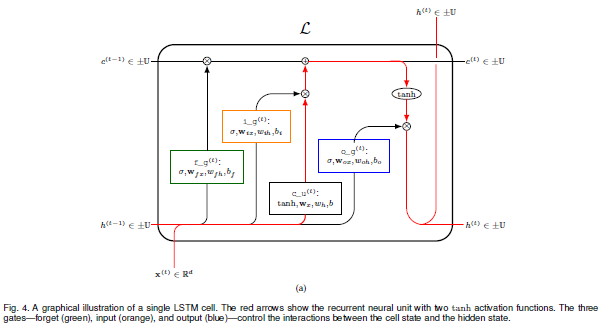
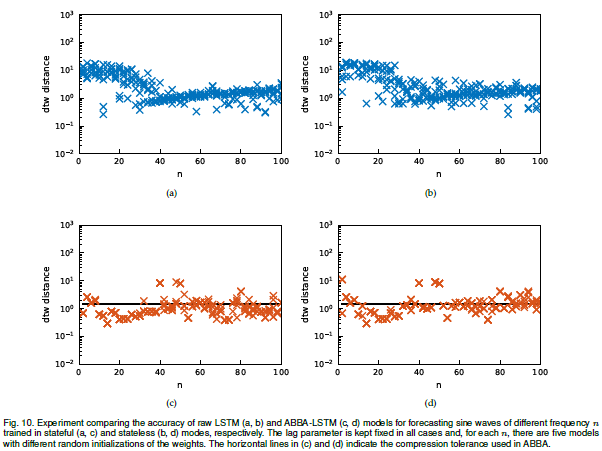
本文使用LSTM对时间序列数据进行预测,为了提高训练的速度,使用了基于聚类的ABBA表征方法,对数据集进行预处理转换为符号的形式,并最终将符号进行数字化,以供LSTM网络使用。
本文对数据符号化的方法进行了优化,采用了插值的方法,让转化出来的时间序列数据更加紧密和平滑,此外,作者从对超参数的敏感度等方面研究了使用预处理过的数据进行训练能比直接使用原始数据进行训练的速度更快的原因。
我以前做车流量预测的时候,突发奇想尝试过将车流量值转化为符号表示,再使用LSTM+attention的网络结构进行训练,效果十分好,这篇文章解答了我当时很多的疑惑。很多数值化的序列数据,经过预处理,能使用自然语言处理的方法来预测,从而能得到更加丰富的上下文信息,不知这样理解是否是对的?
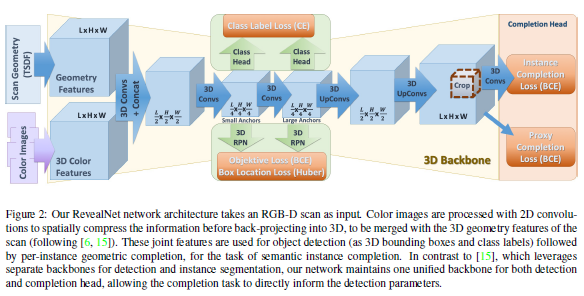
论文名称:RevealNet: Seeing Behind Objects in RGB-D Scans
作者:Hou Ji /Dai Angela /Nießner Matthias
发表时间:2019/4/26
论文链接:https://paper.yanxishe.com/review/14282?from=leiphonecolumn_paperreview0331
推荐原因
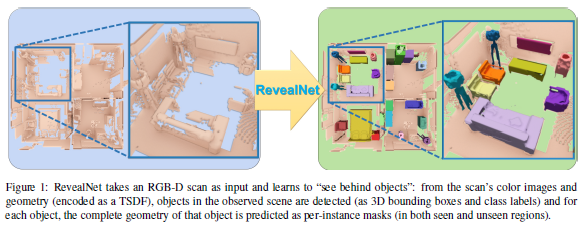
本文已被CVPR2020接收。在3D重建的过程中,人体通常无法扫描每个视图下的所有单个对象,这会导致扫描数据的的丢失,进而限制很多应用,如机器人需要了解一个没见过的几何体以进行精确的抓取。
本文作者介绍了一个语义实例补全的任务:从一个不完全的RGBD扫描场景数据,来检测每个物体实例并推断其完整的几何形状。为了解决这个问题,作者提出了一个端到端的3D神经网络架构RevealNet,通过数据驱动的方法来联合检测实例对象并预测其完整的几何形状。这使得扫描的场景能够被有语义的分割为独立的完整的3D物体,包括遮挡的和没有观察到的物体部分。文章方法比目前的最优方法在mAP@0.5的衡量标准下效果有大幅提升,在ScanNet数据集上有15的提升,在SUNCG数据集上有18的提升。
文章介绍了一个3D机器学习任务:语义实例补全,并提出了一个有效的框架RevealNet解决该任务。
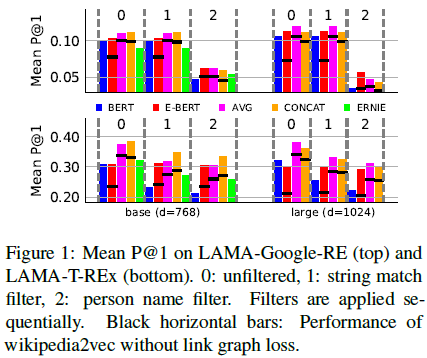
论文名称:BERT is Not a Knowledge Base (Yet): Factual Knowledge vs. Name-Based Reasoning in Unsupervised QA
作者:Nina Poerner∗† and Ulli Waltinger† and Hinrich Schutze ¨ ∗
发表时间:2019/11/9
论文链接:https://paper.yanxishe.com/review/14281?from=leiphonecolumn_paperreview0331
推荐原因
作者发现一些特殊问题:很难从句子中的实体名称推理而出但是实际上并不困难,对于BERT而言很难处理,从而质疑BERT能从名称推理出答案,但是并不足以称之为一个知识库。同时提出了一种将由维基百科预料中学到的词向量嵌入到BERT模型中的扩展模型,得到了比BERT和ERNIE更好的结果。
作者提出的扩展模型,引入了词向量嵌入,在特定的任务上提升了BERT的效果,相对于需要在额外知识库中进行预训练得到的嵌入信息,更加简便,可解释性也更强。
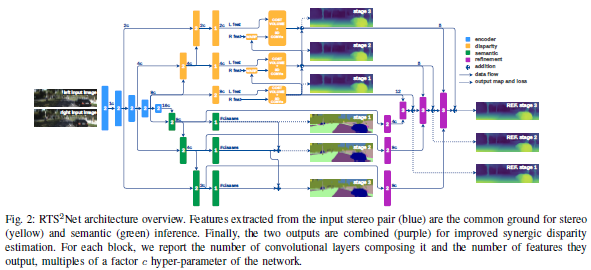
论文名称:Real-Time Semantic Stereo Matching
作者:Dovesi Pier Luigi /Poggi Matteo /Andraghetti Lorenzo /Martí Miquel /Kjellström Hedvig /Pieropan Alessandro /Mattoccia Stefano
发表时间:2019/10/1
论文链接:https://paper.yanxishe.com/review/14231?from=leiphonecolumn_paperreview0331
推荐原因
这篇论文提出了第一实时的语义立体匹配网络RTSSNet,即将语义分割和双目深度估计两个任务用同一个端到端的网络来实现,并且达到实时的速度。之前的论文有将语义分割和立体匹配相结合(如SegStereo),但是他们并没有达到实时的速度。这篇论文提出的RTSSNet结构包括4个金字塔模块,(1)特征提取模块;(2)视差估计模块;(3)语义分割模块;(4)协同视差优化模块。第一个模块是两个任务共享的;第二和第三个模块分别对应两个任务,并且具有分辨率逐渐递增的三个阶段,用来平衡准确率和速度;第四个模块用来进一步的将语义信息和深度信息融合,获得更准确的视差图。这篇论文发表在机器人顶会ICRA 2020上,关注的智能机器人在场景感知上的需求——既要知道目标在哪里(深度信息),还要知道目标是什么(语义信息)。具有很强的实际用途。


雷锋网雷锋网雷锋网
相关文章:

正在生成分享图...
 张璐
昨天 14:22
陈淑瑜
06月12日 16:38
郑佳美
06月12日 14:28
郑佳美
06月12日 14:25
张璐
昨天 14:22
陈淑瑜
06月12日 16:38
郑佳美
06月12日 14:28
郑佳美
06月12日 14:25