
基于进化算法和权值共享的神经网络结构搜索
检测视频中关注的视觉目标
包含状态信息的弱监督学习方法进行人物识别
基于解剖学感知的视频3D人体姿态估计
RandLA-Net:一种新型的大规模点云语义分割框架
论文名称:CARS: Continuous Evolution for Efficient Neural Architecture Search
作者:Zhaohui
发表时间:2020/3/4
论文链接:https://paper.yanxishe.com/review/13531?from=leiphonecolumn_paperreview0312
推荐原因
本文为2020CVPR的文章,是国内华为公司的一篇paper。本文的主要工作是为了优化进化算法在神经网络结构搜索时候选网络训练过长的问题,作者参考了ENAS和NSGA-III。在此基础上,作者提出了一种新的方法——连续进化结构搜索(continuous evolution architecture search),简记为CARS。该方法尽可能的利用学习到的一切知识,包括上一轮训练的结构和参数。
创新点:
1、开发了一种有效的连续进化方法用于搜索神经网络。可以在训练数据集上调整最新一代共享一个SuperNet中参数的总体架构。
2、使用None-dominated排序策略来选择不同大小的优秀网络,整体耗时仅需要0.5 GPU day。

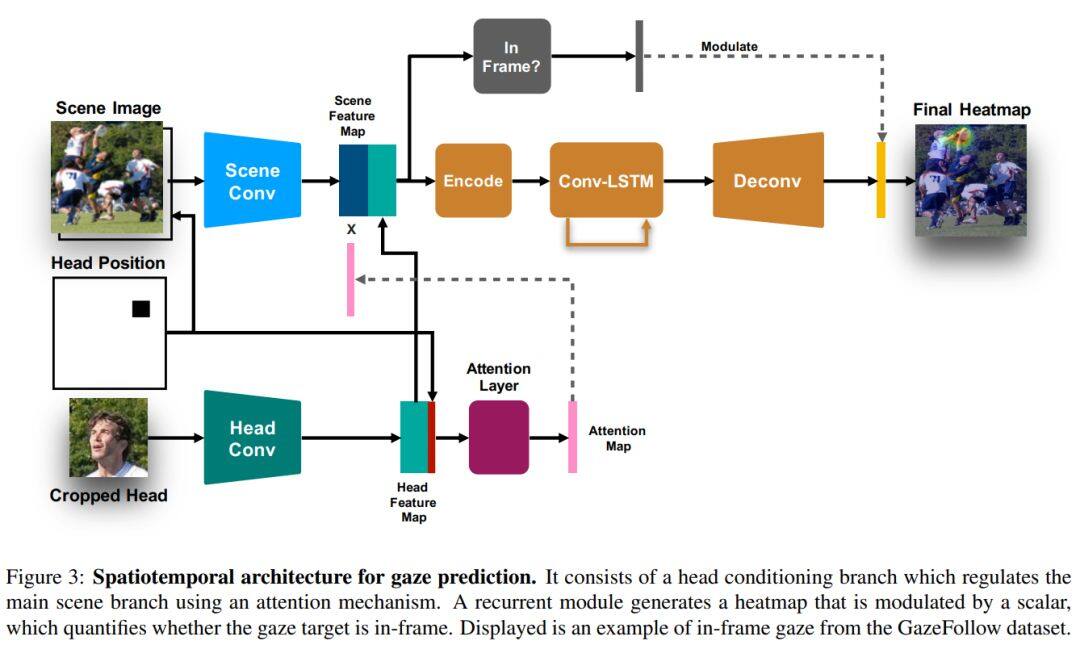
论文名称:Detecting Attended Visual Targets in Video
作者:Chong Eunji /Wang Yongxin /Ruiz Nataniel /Rehg James M.
发表时间:2020/3/5
论文链接:https://paper.yanxishe.com/review/13533?from=leiphonecolumn_paperreview0312
推荐原因
这篇论文被CVPR 2020接收,要解决的是检测视频中关注目标的问题。具体来说,目标是确定每个视频帧中每个人的视线,并正确处理帧外(的情况。所提的新架构有效模拟了场景与头部特征之间的动态交互,以推断随时间变化的关注目标。同时这篇论文引入了一个新数据集VideoAttentionTarget,包含现实世界中复杂和动态的注视行为模式。在该数据集上进行的实验表明,所提模型可以有效推断视频中的注意力。为进一步证明该方法的实用性,这篇论文将预测的注意力图应用于两个社交注视行为识别任务,并表明所得分类器明显优于现有方法。

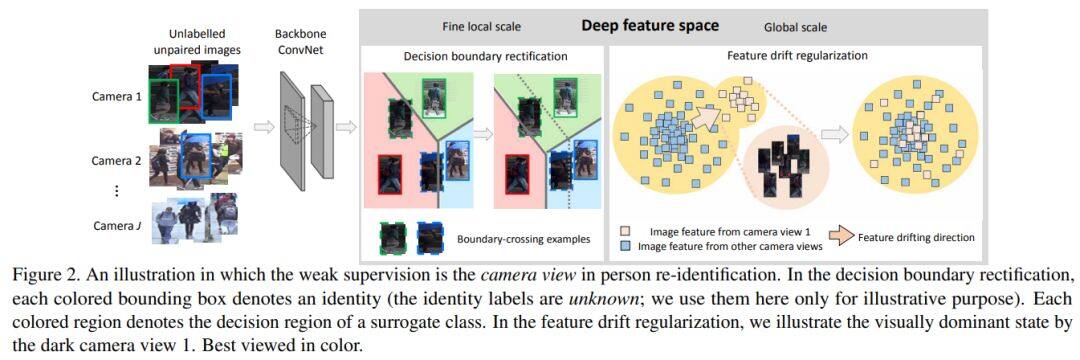
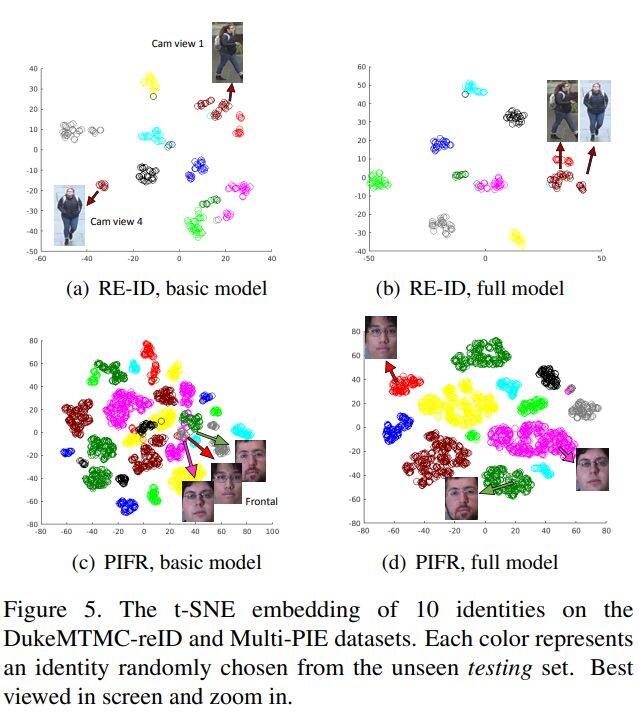
论文名称:Weakly supervised discriminative feature learning with state information for person identification
作者:Yu Hong-Xing /Zheng Wei-Shi
发表时间:2020/2/27
论文链接:https://paper.yanxishe.com/review/13409?from=leiphonecolumn_paperreview0312
推荐原因
这篇论文提出使用状态信息的弱监督学习实现行人识别的方法。
在获取人工标注的训练数据代价太高的现实下,使用非监督学习来识别每个行人不同的视觉特征具有很重要的意义。但由于如摄像头拍摄位置角度不同等状态差异,同一个体的照片都会存在视觉差别,给无监督分类学习带来了巨大困难。而本文就提出了能够利用这些不需要人工标注的状态信息(如摄像头位置或脸部拍摄角度标注)的弱监督学习方法,该方法使用状态信息优化了假定类别的决策边界,以及使用状态信息调节控制了识别特征的偏移。论文在Duke-reID, MultiPIE 和CFP数据集上进行测试,结果远优于其它现有方法,同时论文的模型和标准的有监督学习模型也进行了比较相较,并显示出相当的性能。文章代码可见https: //github.com/KovenYu/state-information.
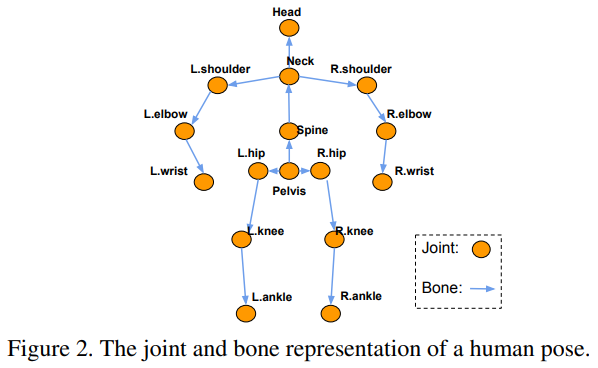
论文名称:Anatomy-aware 3D Human Pose Estimationin Video
作者:Tianlang Chen
发表时间:2020/2/1
论文链接:https://paper.yanxishe.com/review/13408?from=leiphonecolumn_paperreview0312
推荐原因
研究意义:
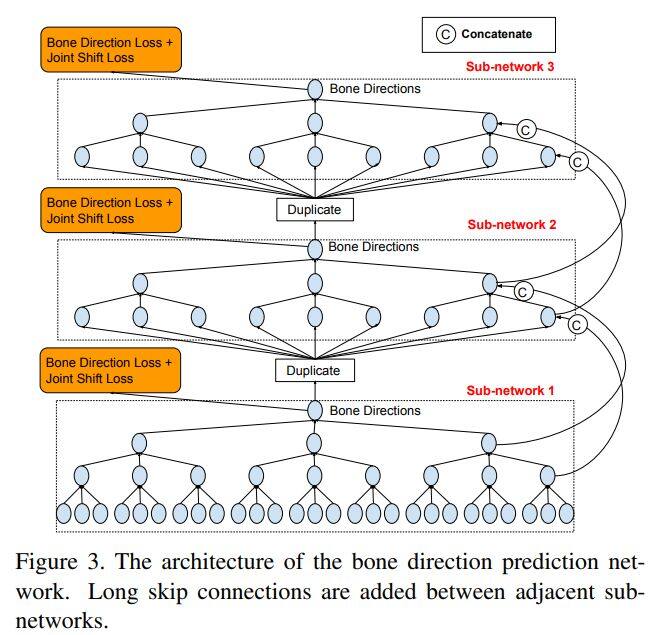
本文提出了一种新的视频中3D人体姿态估计的解决方案。与传统的研究进行对比,本文不是直接根据3D关节位置进行研究,而是从人体骨骼解剖的角度出发,将任务分解为骨骼方向预测和骨骼长度预测,从这两个预测中完全可以得到三维关节位置。
创新点:
1、本文提出了一种具有长跳跃连接的全卷积传播结构,用于骨骼方向的预测。该网络结构可以实现在分层预测不同骨骼的方向时,而不使用任何耗时的存储单元(例如LSTM)。
2、采用一种隐含的注意机制将2D关键点可见性分数作为额外的指导反馈到模型中,这显著地缓解了许多具有挑战性的姿势中的深度歧义。
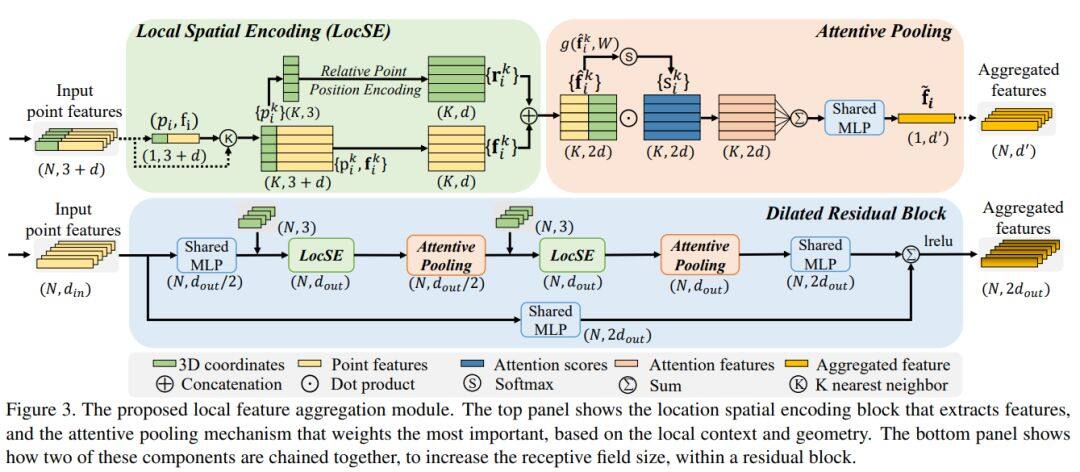
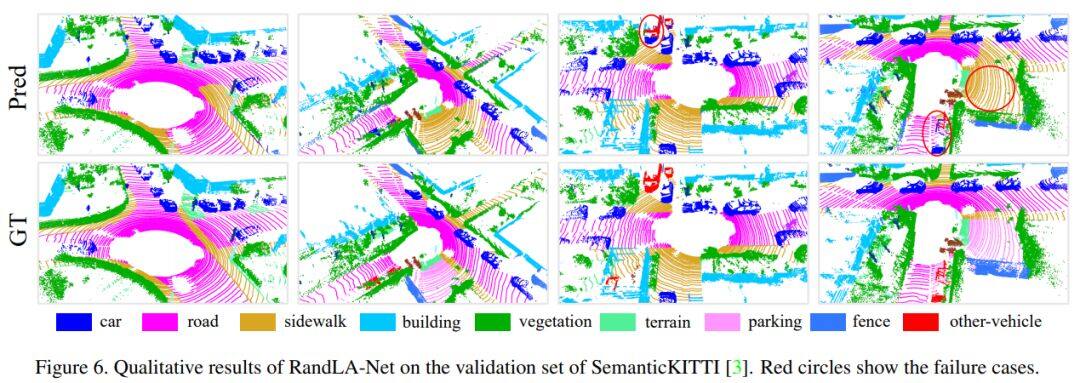
论文名称:RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds
作者:Qingyong Hu
发表时间:2020/2/1
论文链接:https://paper.yanxishe.com/review/13407?from=leiphonecolumn_paperreview0312
推荐原因
本文的核心:
作者主要介绍了RandLA-Net网络框架来推断大规模点云上的per-point semantics。之所以采用随机点采样而不是更复杂点的选择方法,是因为可以大大减少内存占用的框架计算成本。此外,作者还引入了一种新颖的局部特征聚合模块,通过使用轻量级的网络体系结构,最终证明了RandLA-Net网络框架可以有效地用来解决大规模点云问题。
创新点:
作者提出了一种基于简单高效的随机将采样和局部特征聚合的网络结构(RandLA-Net)。该方法在数据集Semantic3D和SemanticKITTI等大场景点云分割数据集上都取得了非常好的效果,从而验证了该方法的优良性,此外通过实验发现,采用本文提出的网络框架,计算效率也是非常高的,明显优于其它模型。

雷锋网雷锋网雷锋网
相关文章:

正在生成分享图...