
使用混合精度的方法在GPU集群上进行深度循环神经网络的训练
PoseNet3D:无监督的3D人体形状和姿态估计
AET vs. AED:无监督表示学习通过自编码变换而不是自编码数据
基于注意力的视点选择网络用于光场视差估计
基于CNN的中文lexicon rethinking NER模型
论文名称:Training distributed deep recurrent neural networks with mixed precision on GPU clusters
作者:Alexey Svyatkovskiy / Julian Kates-Harbeck / William Tang
发表时间:2019/11/30
论文链接:https://paper.yanxishe.com/review/13855?from=leiphonecolumn_paperreview0326
推荐原因
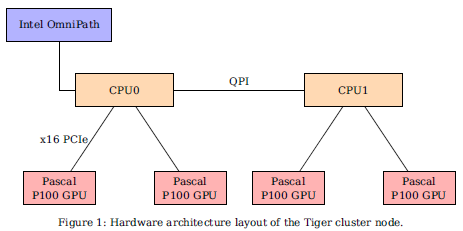
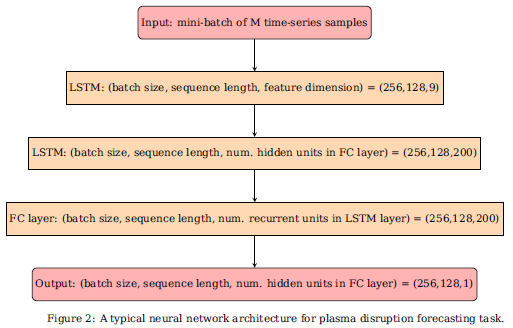
核心问题:本文从硬件选取、模型搭建、分布式计算策略、学习率、损失函数等方面,非常详细的讲解了如何高效使用多达100个GPU进行深度循环神经网络
创新点:本文没有相关工作的部分,贵在务实,从实际的研究工作中部署一个高效的GPU集群的角度,讨论了如何将分布式计算策略、基于混合精度的训练模型结合起来,使得模型的训练速度加快、内存消耗降低,并且模型的表现分数并不会下降。同时,作者还研究了使用参数来对损失函数进行缩放,以此提高模型在集群环境下的收敛速度
研究意义:无论是循环神经网络,还是卷积神经网络,模型的规模越来越大,本文作者所提出的各种技巧,能解决训练过程实际的问题,一方面,能在保证了模型的准确率的情况下减少训练的成本,另一方面,也有助于在当前的资源下,训练更大的模型。
这些技巧主要针对GPU集群环境,但也能给单GPU环境的同学提供参考。
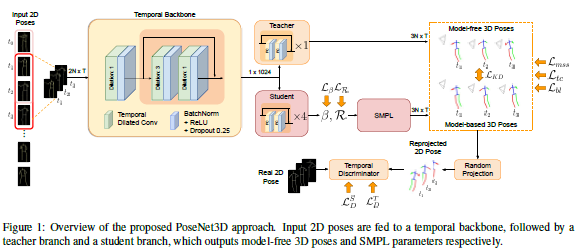
论文名称:PoseNet3D: Unsupervised 3D Human Shape and Pose Estimation
作者:Tripathi Shashank /Ranade Siddhant /Tyagi Ambrish /Agrawal Amit
发表时间:2020/3/7
论文链接:https://paper.yanxishe.com/review/13853?from=leiphonecolumn_paperreview0326
推荐原因
从二维关节中恢复三维人体姿态是一个高度无约束的问题。本文作者提出了一种新的神经网络框架PoseNet3D,其以2D关节点作为输入,输出3D骨架和SMPL人体模型的参数。作者使用了学生-老师框架,从而避免了在训练过程中使用3D数据如配对/未配对的3D数据、动捕数据、深度图或者多视角图像等等。作者首先使用2D人体关键点训练了一个教师网络输出3D人体骨架,教师网络将其知识提取到学生网络中,然后学生网络预测基于SMPL人体模型表达的3D人体姿态。
作者的方法在Human3.6M数据集上相比之前无监督的方法,3D关节点预测误差减少了18%。在自然数据集上,文章方法恢复的人体姿态和网格也是较为自然、真实的,在连续帧上预测结果也比较连续。

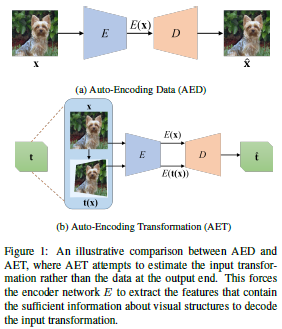
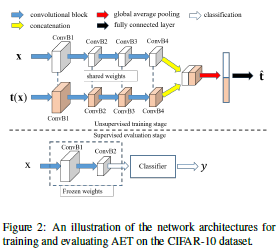
论文名称:AET vs. AED: Unsupervised Representation Learning by Auto-Encoding Transformations rather than Data
作者:Zhang Liheng /Qi Guo-Jun /Wang Liqiang /Luo Jiebo
发表时间:2019/1/14
论文链接:https://paper.yanxishe.com/review/13851?from=leiphonecolumn_paperreview0326
推荐原因
这篇论文提出了一种新的通用的无监督表示学习框架——自编码变换(Auto-Encoding Transformation,AET)。经典的自编码数据框架的输入是图像,采用编码-解码网络得到重构之后的图像。而自编码变换的输入是常见的变换(如旋转,射影变换,放射变换等),即图像和经过变换之后的图像,经过编码-解码结构之后得到重构的变换,重构的变换和原始的变换使用MSE作为损失函数,这对于参数化和非参数化的变换,以及GAN都是有效的。作者通过实验表明,通过重构变换可以提取到更加丰富并且具有判别性的特征,当自编码变换网络训练完毕之后,使用编码部分的网络结构和权重就可以作为一种特征提取器,从而泛化到其他具体任务上。作者利用NIN网络,分别采用基于模型的分类器和不基于模型的分类器(KNN)进行图像分类实现,其性能比之前的无监督方法要优越。该论文收录在CVPR 2019,其提出的新的通用的无监督表示学习框架对无监督学习具有很大的启发作用。
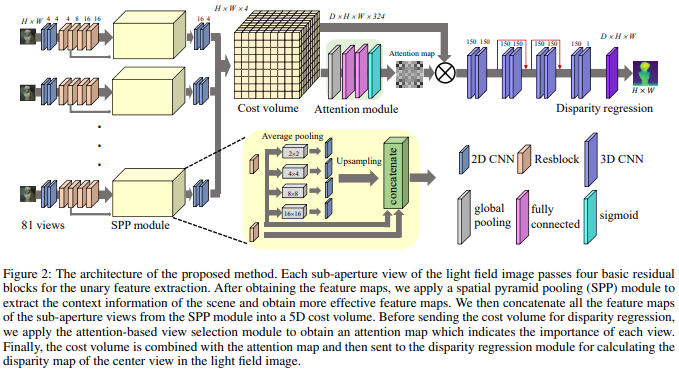
论文名称:Attention-based View Selection Networks for Light-field Disparity Estimation
作者:Yu-Ju Tsai / Yu-Lun Liu / Ming Ouhyoung / Yung-Yu Chuang
发表时间:2020/2/1
论文链接:https://paper.yanxishe.com/review/13680?from=leiphonecolumn_paperreview0326
推荐原因
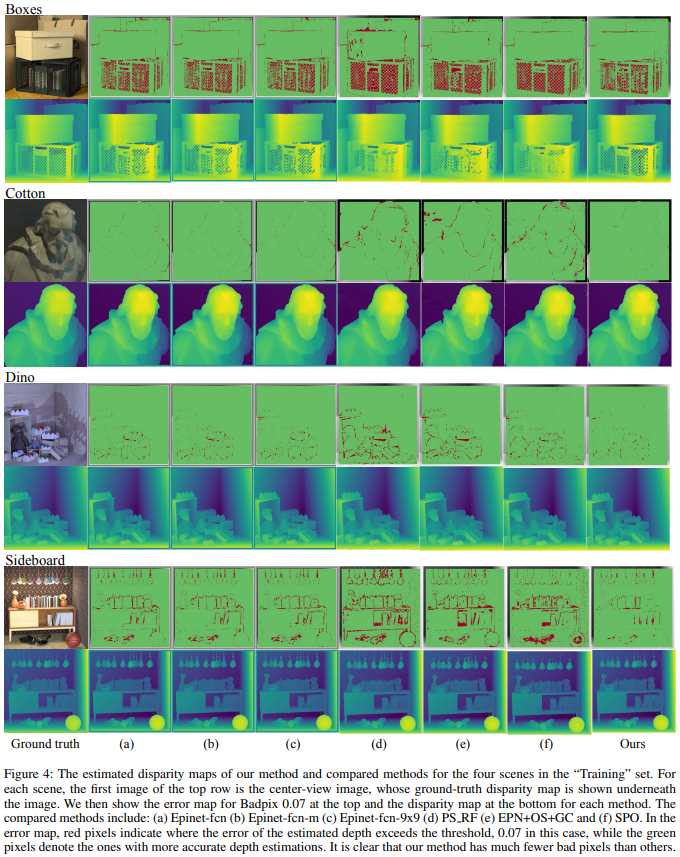
这篇论文是用来解决光场图像(Light-fifield)的深度估计问题。对于光场图像,其输入是同一个物体多个不同视角的图像,作者认为这些视角之间具有很大的重叠,在提取特征时是存在重复和冗余现象的。由此,作者提出了一个基于注意力机制的视角选择网络,作为多个视角特征的重要性衡量权重,从而去除一些重叠和冗余的视角。具体来说,是借鉴双目深度估计的PSMNet网络结构,在匹配代价体(cost volume)之后插入一个基于注意力的视角选择网络。网络的输出是0-1的权重,按照构造形式可以分为无约束的(free),对称型的(symmetric)和放射状的(radial)三种形式,并且学习的参数量逐渐减少。这篇论文的想法比较直接,但是确实能取得当前光场图像深度估计的最佳性能,收录在AAAI 2020。
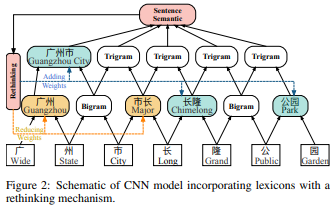
论文名称:CNN-Based Chinese NER with Lexicon Rethinking
作者:Tao Gui
发表时间:2019/11/6
论文链接:https://paper.yanxishe.com/review/13548?from=leiphonecolumn_paperreview0326
推荐原因
本文研究意义:
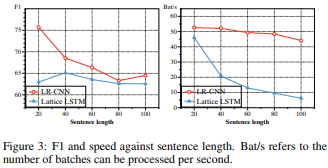
采用长时短期记忆(LSTM)对字符级中文命名实体识别(NER)目前已经实现了不错的效果,然而当我们在具体工程化落地的过程中,会出现GPU在并行性计算的时候会和候选词之间发生冲突的问题,针对这一问题,作者建议采用更快卷积神经网络CNN重新构建模型,因为LSTM是一种时序网络不能够进行并行化计算,而CNN是可以进行并行化计算。通过实验表明,作者所提出的方法可以执行比最先进的方法快3.21倍,同时实现更好的性能。

雷锋网雷锋网雷锋网
相关文章:

正在生成分享图...
 张璐
昨天 14:22
陈淑瑜
06月12日 16:38
郑佳美
06月12日 14:28
郑佳美
06月12日 14:25
张璐
昨天 14:22
陈淑瑜
06月12日 16:38
郑佳美
06月12日 14:28
郑佳美
06月12日 14:25