
视觉对话的模态平衡模型
对注意力的通用攻击和对应的数据集DAmageNet
半结构化表的组合语义分析
从输入输出示例合成高表达性SQL查询
DeeperCut: 一种更深入,更强,更快速的多人姿态估计模型
论文名称:Modality-Balanced Models for Visual Dialogue
作者:Kim Hyounghun /Tan Hao /Bansal Mohit
发表时间:2020/1/17
论文链接:https://paper.yanxishe.com/review/9325
推荐原因
这篇论文考虑的是视觉对话问题。
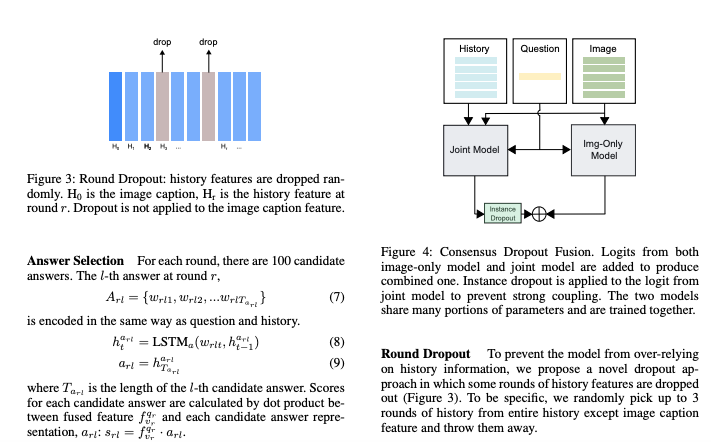
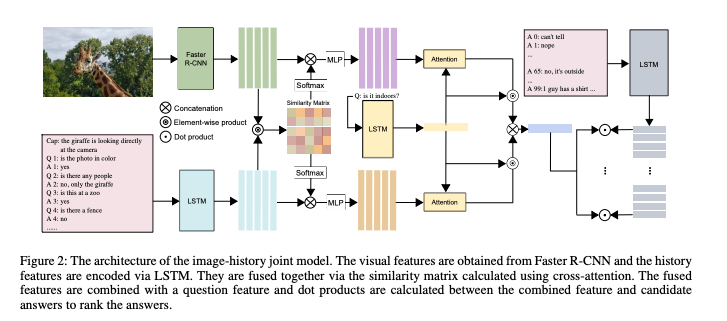
视觉对话任务需要一个模型来利用图像和对话以生成针对当前对话的下一个响应。然而存在大量对话问题是不需要通过任何上下文历史信息就可以根据查询图像而得以解答。这篇论文认为以往的联合模式(历史加图像信息)模型过于依赖且更易记住对话历史,而仅图像模型更加具有通用性,并且在允许多个正确答案时表现更好。因此这篇论文鼓励维护两个模型,即仅图像模型和图像-历史联合模型,并将它们的互补能力结合起来以形成更平衡的多峰模型。这篇论文通过集成和共有参数的共识落差融合,提出了两种方法用于这两个模型的集成,并且在2019年视觉对话挑战赛上取得了出色的成绩。

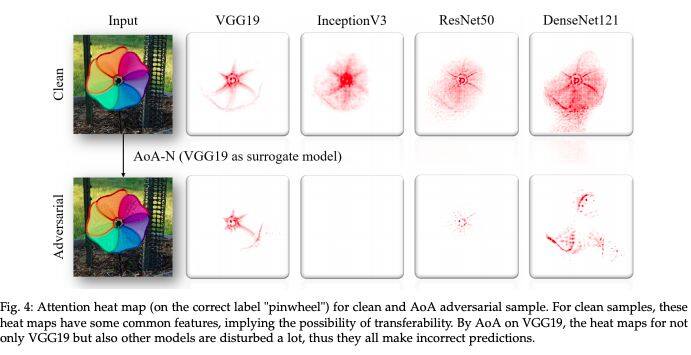
论文名称:Universal Adversarial Attack>作者:Chen Sizhe /He Zhengbao /Sun Chengjin /Huang Xiaolin
发表时间:2020/1/16
论文链接:https://paper.yanxishe.com/review/9324
这篇论文研究的是深度神经网络的对抗性攻击。这篇论文提出了注意力集中攻击(Attack _src="https://notecdn.yiban.io/cloud_res/79539/imgs/20-2-7_03:41:29.935_70700.png" style="max-width: 100%; border-style: solid; border-width: 0px; box-shadow: none; height: auto !important; visibility: visible !important;">


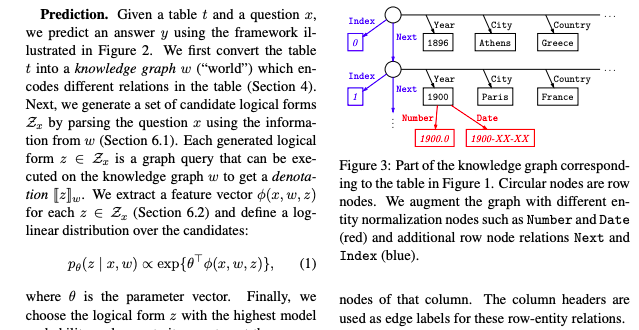
论文名称:Compositional Semantic Parsing>作者:Panupong Pasupat /Percy Liang
发表时间:2015/1/24
论文链接:https://paper.yanxishe.com/review/9240
推荐原因
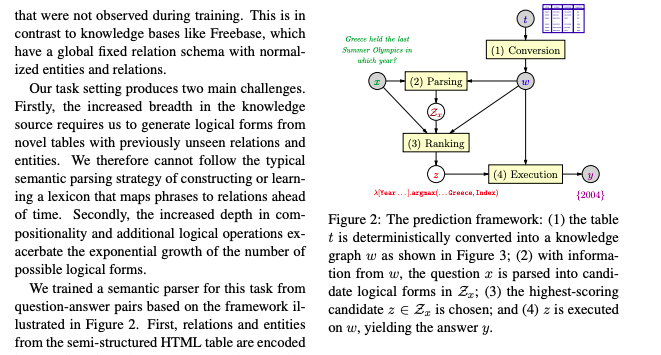
核心问题:本文完成的是一个问答系统
创新点:本文训练了一个语义分析器,首先将关系和实体从半结构化HTML表中编码。然后,系统分析问题成为覆盖率高的候选逻辑形式语法,用对数线性重新排列候选项模型,然后执行得分最高的逻辑形式来产生答案的表示
研究意义:作者构建了一个数据集,在这个数据集的效果证实了,这种方法比传统的基准模型要好。

论文名称:Synthesizing Highly Expressive SQL Queries from Input-Output Examples
作者:Chenglong Wang /Alvin Cheung /Rastislav Bodik
发表时间:2017/1/5
论文链接:https://paper.yanxishe.com/review/9239
推荐原因
核心问题:SQL语言具有特定的语法结构,这就导致要想熟练使用SQL语言需要较高的门槛,本论文就是解决这个问题,
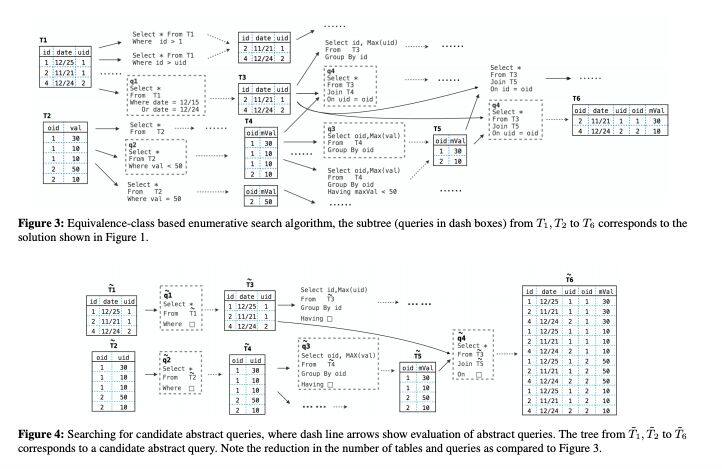
创新点:本论文开发一种如下的方式:
新的抽象-抽象查询语言-分解原来具有挑战性的综合问题。
这种语言中的抽象查询在语法上类似于SQL查询,但筛选器谓词替换为可以用任何有效谓词。总的来说就是分为两个过程,第一个过程是可能实例化为SQL的抽象查询。第二个过程是为每个合成抽象查询,将其实例化为所需的SQL查询并将顶级候选项返回给用户。
研究意义:自从抽象查询中的运算符不再由参数化谓词,抽象查询的搜索空间显著比原来的减少了

论文名称:DeeperCut: A Deeper, Stronger, and Faster Multi-Person Pose Estimation Model
作者:Insafutdinov Eldar /Pishchulin Leonid /Andres Bjoern /Andriluka Mykhaylo /Schiele Bernt
发表时间:2016/5/10
论文链接:https://paper.yanxishe.com/review/9238
推荐原因
研究目标:多人场景中提高关节姿态估计的技术水平
改进了DeepCut
(1)改进的体部检测器,为体部生成有效的自底向上的建议;
(2)新颖的、以图像为条件的成对术语,允许将建议组合成数量可变的、一致的身体部分配置;
(3)增量优化策略,更有效地探索搜索空间,从而导致更好的性能和显著的加速因素。
在两个单人和两个多人位姿估计基准上进行评估。该方法显著优于最著名的多人姿态估计结果,同时在单人姿态估计任务中表现出了较强的竞争能力。
模型和代码可以从http://pose.mpi-inf.mpg.de获得
ECCV 2016



为了更好地服务广大 AI 青年,AI 研习社正式推出全新「论文」版块,希望以论文作为聚合 AI 学生青年的「兴趣点」,通过论文整理推荐、点评解读、代码复现。致力成为国内外前沿研究成果学习讨论和发表的聚集地,也让优秀科研得到更为广泛的传播和认可。
我们希望热爱学术的你,可以加入我们的论文作者团队。
加入论文作者团队你可以获得
1.署着你名字的文章,将你打造成最耀眼的学术明星
2.丰厚的稿酬
3.AI 名企内推、大会门票福利、独家周边纪念品等等等。
加入论文作者团队你需要:
1.将你喜欢的论文推荐给广大的研习社社友
2.撰写论文解读
如果你已经准备好加入 AI 研习社的论文兼职作者团队,可以添加运营小姐姐的微信,备注“论文兼职作者”

相关文章:
今日 Paper | 多人姿势估计;对话框语义分析;无监督语义分析;自然语言处理工具包等
今日 Paper | 多人线性模型;身体捕捉;会话问答;自然语言解析;神经语义
今日 Paper | 手部和物体重建;三维人体姿态估计;图像到图像变换等
今日 Paper | 动态手势识别;领域独立无监督学习;基于BERT的在线金融文本情感分析等
今日 Paper | 新闻推荐系统;多路编码;知识增强型预训练模型等
今日 Paper | 小样本学习;视觉情感分类;神经架构搜索;自然图像抠像等
今日 Paper | 蚊子叫声数据集;提高语音识别准确率;对偶注意力推荐系统等
今日 Paper | 人脸数据隐私;神经符号推理;深度学习聊天机器人等
今日 Paper | 虚拟试穿网络;人群计数基准;联邦元学习;目标检测等
今日 Paper | 人体图像生成和衣服虚拟试穿;鲁棒深度学习;图像风格迁移等
今日 Paper | 随机微分方程;流式自动语音识别;图像分类等
今日 Paper | 高维感官空间机器人;主动人体姿态估计;深度视频超分辨率;行人重识别等
今日 Paper | 3D手势估计;自学习机器人;鲁棒语义分割;卷积神经网络;混合高斯过程等
今日 Paper | 精简BERT;面部交换;三维点云;DeepFakes 及 5G 等

正在生成分享图...