
REFORMER:一个高效的TRANSFORMER结构
具有文本指导的图像到图像的翻译
解决背景重校准损失下的缺失标注目标检测问题
MLFcGAN:基于多级特征融合的条件GAN水下图像颜色校正
基于跨模态自我注意网络学习的视频问题生成
论文名称:REFORMER: THE EFFICIENT TRANSFORMER
作者:Nikita Kitaev / Lukasz Kaiser / Anselm Levskaya
发表时间:2019/9/26
论文链接:https://paper.yanxishe.com/review/11542?from=leiphonecolumn_paperreview0221
推荐原因
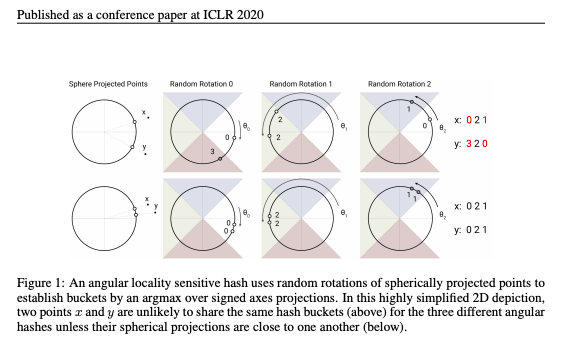
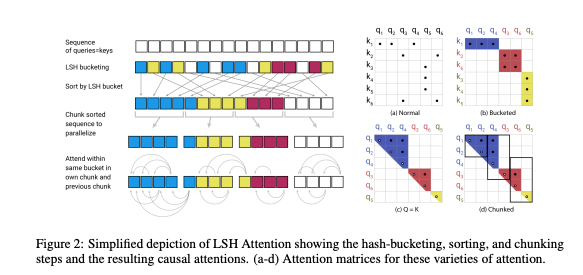
核心问题:自从BERT取得了巨大的效果的时候,transform就成为了大多数nlp任务的标配,但是它存在一些问题,比如训练速度慢,占用内容大,还有无法处理长序列,本论文就是解决这些问题。
创新点:该论文提出了一种REFORMER结构,它的核心有以下几点:首先提出了可逆层,在该层中只存储单层激活值的一份拷贝,然后它把FF层里的激活值进行切分 ,最后它使用局部敏感哈希(LSH)注意力代替传统多头注意力
研究意义:这个新模型不仅训练速度快,而且占用内存小,还可以解决序列过长的问题。
论文名称:Image-to-Image Translation with Text Guidance
作者:Li Bowen /Qi Xiaojuan /Torr Philip H. S. /Lukasiewicz Thomas
发表时间:2020/2/12
论文链接:https://paper.yanxishe.com/review/11541?from=leiphonecolumn_paperreview0221
推荐原因
这篇论文提出了一个新的图像到图像迁移方法,通过生成对抗网络将可控因素(即自然语言描述)嵌入到图像到图像的迁移中,从而使文字描述可以确定合成图像的视觉属性。这个新方法由4个关键组成部分组成:1、实施词性标注以过滤掉给定描述中的非语义词;2、采用仿射组合模块来有效融合不同形式的文本和图像特征;3、一种新的精细多级架构,以增强判别器的判别能力和生成器的纠正能力;4、一种新的结构损失,进一步提升了判别器的性能,以更好地区分真实图像和合成图像。COCO数据集上的实验表明了这篇论文提出的方法在视觉真实性和语义一致性方面均具有出色的性能表现。


论文名称:Solving Missing-Annotation Object Detection with Background Recalibration Loss
作者:Zhang Han /Chen Fangyi /Shen Zhiqiang /Hao Qiqi /Zhu Chenchen /Savvides Marios
发表时间:2020/2/12
论文链接:https://paper.yanxishe.com/review/11540?from=leiphonecolumn_paperreview0221
推荐原因
这篇论文研究了一种新的且具有挑战性的目标检测场景:数据集中大多数真实对象或实例未被标注,因此这些未被标注的区域在训练过程中被视为背景。现有方法基于Faster RCNN,使用软采样与正实例的重叠来对RoI的梯度进行加权。这篇论文提出了一个新的名为背景重校准损失的解决方案,可以根据预定义的IoU阈值和输入图像来自动重新校准损失信号。这篇论文还进行了几项重大的修改,以适应缺失标注的情况。PASCAL VOC和MS COCO数据集上的实验表明这篇论文所提出的方法在很大程度上优于现有方法。

论文名称:MLFcGAN: Multi-level Feature Fusion based Conditional GAN for Underwater Image Color Correction
作者:Liu Xiaodong /Gao Zhi /Chen Ben M.
发表时间:2020/2/13
论文链接:https://paper.yanxishe.com/review/11539?from=leiphonecolumn_paperreview0221
推荐原因
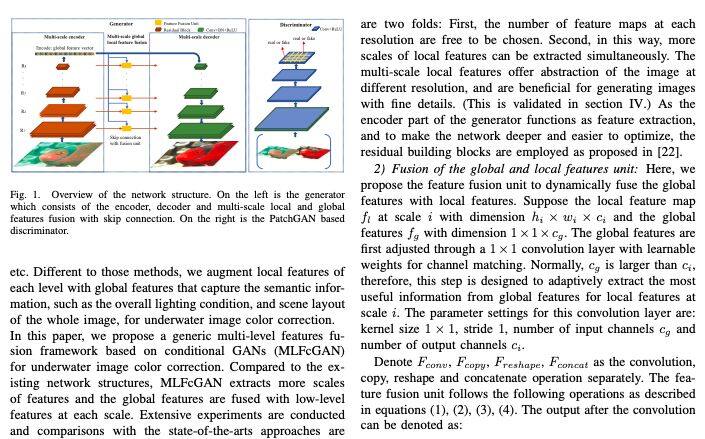
这篇论文考虑的是水下图像的色彩修正问题。
这篇论文基于生成对抗网络,提出了一个深度多尺度特征融合网络,首先抽取多尺度特征,然后在每个尺度用全局特征对局部特征进行了增强。在色彩修正和细节保留两个任务上,这篇论文所提方法取得领先优势,在质量、呈现效果、方法新颖上相比当前最佳模型更加优越。

论文名称:Video Question Generation via Cross-Modal Self-Attention Networks Learning
作者:Wang Yu-Siang /Su Hung-Ting /Chang Chen-Hsi /Liu Zhe-Yu /Hsu Winston
发表时间:2019/7/5
论文链接:https://paper.yanxishe.com/review/11538?from=leiphonecolumn_paperreview0221
推荐原因
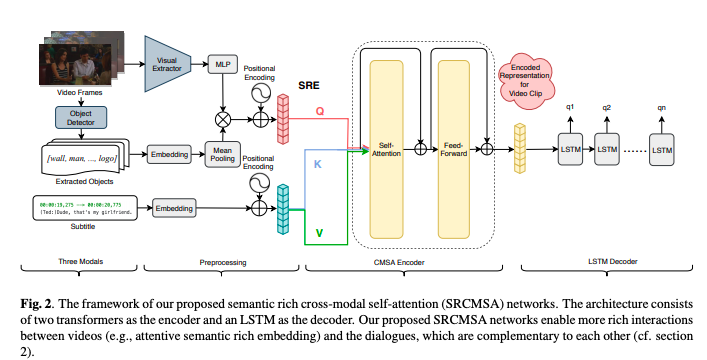
这篇论文要解决的是视频问答的问题。
对视频问答任务而言,深度学习模型严重依赖海量数据,而这类数据的标注成本很高。这篇论文提出了一个新任务,可以自动根据视频片段中的视频帧序列和相应的字幕生成问题,从而减少了巨大的标注成本。学习如何对视频内容进行提问需要模型理解场景中丰富的语义以及视觉和语言之间的相互作用。为了解决这个问题,这篇论文提出了一种新的跨模式自注意力网络,以聚合视频帧和字幕的各种特征。通过实验证明了所提出的方法相对于基准方法可以有85%的提升。

为了更好地服务广大 AI 青年,AI 研习社正式推出全新「论文」版块,希望以论文作为聚合 AI 学生青年的「兴趣点」,通过论文整理推荐、点评解读、代码复现。致力成为国内外前沿研究成果学习讨论和发表的聚集地,也让优秀科研得到更为广泛的传播和认可。
我们希望热爱学术的你,可以加入我们的论文作者团队。
加入论文作者团队你可以获得
1.署着你名字的文章,将你打造成最耀眼的学术明星
2.丰厚的稿酬
3.AI 名企内推、大会门票福利、独家周边纪念品等等等。
加入论文作者团队你需要:
1.将你喜欢的论文推荐给广大的研习社社友
2.撰写论文解读
如果你已经准备好加入 AI 研习社的论文兼职作者团队,可以添加运营小姐姐的微信,备注“论文兼职作者”

雷锋网雷锋网雷锋网
相关文章:

正在生成分享图...